I have been catching a load of grief over my random data post. Folks didn't like my procedure for loading the data, and folks didn't like that I said the EXCEPTIONS INTO seemed to be exhibiting anomalous behavior.
As to the first point, was I attempting to create a picture perfect, bullet proof general purpose data loader that was elegant, fully self documenting and blessed by all and sundry Oracle deities? No. Was I attempting to solve an immediate problem as quickly as possible? Yes. Did the procedure work for that? Yes.
As to the EXCEPTIONS clause, my understanding of an exception is that you get a ordinal value, a "zero" case, then, when duplicates (in the case of a primary key) are found, they are exceptions however, as has been shown to me, Oracle treats all occurrences, ordinal or not, as exceptions. So, Oracle is working as programmed. Do I agree with that? No. However, it has been that way for years. And darned of they will change it for me, imagine that!
In the SQL Manual they have a terse:
"exceptions_clause - Specify a table into which Oracle places the rowids of all rows violating the constraint. If you omit schema, then Oracle assumes the exceptions table is in your own schema. If you omit this clause altogether, then Oracle assumes that the table is named EXCEPTIONS. The exceptions table must be on your local database."
If you don't have an ordinal row, how can subsequent ones violate it?
In the Administrator's guide they provide a quick overview of the EXCEPTIONS clause with a small example. The small example (a single violation) does show two rows being mapped in the exceptions table. Taking some snippets from there:
“All rows that violate a constraint must be either updated or deleted from the table containing the constraint.” Which is incorrect. What if one of the rows is the proper row? Do I delete or update it? In the situation where there are multiple identical rows, except for a bogus artificial key, this statement would lead someone to believe all the rows needed to be deleted. The section only confuses the matter more if someone comes in with a misunderstanding about how the exception table is populated. A second line: “When managing exceptions, the goal is to eliminate all exceptions in your exception report table.”
Also seems to indicate that every line in the exceptions table is an exception, when there are clear cases where the line will be a valid row, not an exception. It all ties back to the definition of exception.
Here is the complete reference for those that doubt my veracity:
http://download-west.oracle.com/docs/cd/B10501_01/server.920/a96521/general.htm#13282
If I ask, in the following series of numbers how many unique, single digit values are there?
1,1,1,2,2,2,3,3,3,4
The answer is 4 (1,2,3,4) and 6 duplications of the numbers, not 1 (4) and 7 exceptions as Oracle’s exception processing would answer.
If you go into it with my initial understanding of what an exception is, then the documentation seems to confirm that, if you go into it with Oracle's understanding of an exception it proves that. I have asked that a simple definition of what Oracle defines an exception to be to be added if possible to the manuals (SQL and Aministrators guide) however I am meeting with extreme resistance.
So, the behavior noted in my previous blog is not a bug, just the way Oracle works. However, you need to take this into account when dealing with Oracle's EXCEPTIONS INTO clause. I would hate for some one working on critical data to use the same definition of exception I did and delete some very important data. When using the EXCEPTIONS INTO clause, be sure to test on a test platform with non-critical data any UPDATE or DELETE activities planned and completely understand the outcome before applying the usage to production data.
Oh, and for those that want to de-dup tables, accoring to Tom Kyte, here is the fastest method known to man:
http://asktom.oracle.com/pls/ask/f?p=4950:8:::::F4950_P8_DISPLAYID:1224636375004#29270521597750
Saturday, April 30, 2005
Wednesday, April 27, 2005
Random Data
Had an interesting bit of work come my way yesterday. For testing we needed a 600 row table with four fields. The first field had X possible entries, the second had Y and the third had Z with the last entry being a simulated count, one third of which had to be zero.
My thought was to use varray types and populate them with the various possible values, then use dbms_random.value to generate the index values for the various varrays. The count column was just a truncated call to dbms_random in the range of 1 to 600. All of this was of course placed into a procedure with the ability to give it the number of required values.
Essentially:
create or replace procedure load_random_data(cnt in number) as
define varray types;
define varrays using types;
declare loop interator;
begin
initialize varrays with allowed values;
start loop 1 to cnt times
set dbms_rabdom seed to loop interator;
insert using calls to dbms_random.value(1-n) as the indice for the various varrays;
end loop;
commit;
end;
This generated the rows and then using a primary key constraint with the exceptions clause I would then be able to delete the duplicates leaving my good rows.
create exceptions table using $ORACLE_HOME/rdbms/admin/utlexcpt.sql
alter table tab_z add constraint primary key (x,y,z) exceptions into exceptions;
delete tab_z where rowid in (select row_id from exceptions);
Well, the procedure worked as planned. However, when I attempted to use the exceptions clause on a concatenated key it did not work after the first run where it left 99 out of 600 rows it ended up rejecting all of the rows in the table on all subsequent runs! I tried it several times, each time it rejected every row in the table, even though I could clearly see by examining the first hundred or so rows that they weren't all duplicates.
The left me the old fallback of using the selection of the rowid values and then deleteing the min(rowid) values:
delete from tab_z Z
where z.rowid > (
select min(z2.rowid) from tab_z Z2
where Z.X = Z2.X and
Z.Y=Z2.Y and
Z.Z=Z2.Z);
This worked as expected. Of course you have to generate X(n1)*Z(n2)*Y(n3)*tab(n4) rows it seems to get the n4 number of rows where n1-3 are the count of the number of unique values for the given column and n4 is the number of rows in the table. For example, for my 600 rows I ended up needing to generate 30000 rows to get 600 non-dupes on the three index values. In the 30000 rows I ended up with 600 sets of duplicates in the range of 9-80 duplicates per entry. I re-seeded the random function using the loop interator with each pass through the loop.
Of course after all the work with dbms_random I figured out that it would have been easier just to cycle through the possible values for the varrays in a nested looping structure. Of course that would have led to a non-random ordered table. For the work we were doing it would have been ok to do it that way, but I can see other situations where the random technique would be beneficial.
My thought was to use varray types and populate them with the various possible values, then use dbms_random.value to generate the index values for the various varrays. The count column was just a truncated call to dbms_random in the range of 1 to 600. All of this was of course placed into a procedure with the ability to give it the number of required values.
Essentially:
create or replace procedure load_random_data(cnt in number) as
define varray types;
define varrays using types;
declare loop interator;
begin
initialize varrays with allowed values;
start loop 1 to cnt times
set dbms_rabdom seed to loop interator;
insert using calls to dbms_random.value(1-n) as the indice for the various varrays;
end loop;
commit;
end;
This generated the rows and then using a primary key constraint with the exceptions clause I would then be able to delete the duplicates leaving my good rows.
create exceptions table using $ORACLE_HOME/rdbms/admin/utlexcpt.sql
alter table tab_z add constraint primary key (x,y,z) exceptions into exceptions;
delete tab_z where rowid in (select row_id from exceptions);
Well, the procedure worked as planned. However, when I attempted to use the exceptions clause on a concatenated key it did not work after the first run where it left 99 out of 600 rows it ended up rejecting all of the rows in the table on all subsequent runs! I tried it several times, each time it rejected every row in the table, even though I could clearly see by examining the first hundred or so rows that they weren't all duplicates.
The left me the old fallback of using the selection of the rowid values and then deleteing the min(rowid) values:
delete from tab_z Z
where z.rowid > (
select min(z2.rowid) from tab_z Z2
where Z.X = Z2.X and
Z.Y=Z2.Y and
Z.Z=Z2.Z);
This worked as expected. Of course you have to generate X(n1)*Z(n2)*Y(n3)*tab(n4) rows it seems to get the n4 number of rows where n1-3 are the count of the number of unique values for the given column and n4 is the number of rows in the table. For example, for my 600 rows I ended up needing to generate 30000 rows to get 600 non-dupes on the three index values. In the 30000 rows I ended up with 600 sets of duplicates in the range of 9-80 duplicates per entry. I re-seeded the random function using the loop interator with each pass through the loop.
Of course after all the work with dbms_random I figured out that it would have been easier just to cycle through the possible values for the varrays in a nested looping structure. Of course that would have led to a non-random ordered table. For the work we were doing it would have been ok to do it that way, but I can see other situations where the random technique would be beneficial.
Tuesday, April 26, 2005
Ad Nauseum
Ad Nauseum, an interesting term. Usually used to indicate that a subject has continued beyond its useful lifetime. Several experts seem to want to continue on such subjects as index rebuilding, clustering factor discussions and updating data dictionary tables ad nauseum. I for one find it odd they have so much free time. Perhaps I should be complemented they feel this drive to snap at my heals so much.
Note to Oracle: Perhaps you should find more for your experts to do, they seem to be caught in a rut.
I have stated my opinions on the subjects of indexes, clustering factors and data dictionary tables. I see no need to reiterate them. I have recanted incorrect advice I have given in the past. It is time to move on. Aren't there more interesting topics? Or perhaps they find, rather like Pro Wrestling draws a number of viewers, a good bash fest draws in more readers. I guess that is what happens when there is no technical content they can present as their own.
Learning is an iterative process, and during that time mistakes can and will be made. However if every time someone makes a misstatement or an error we bash them about the head and shoulders and then remind them of their past mistakes at every opportunity, they will soon cease learning altogether. Makes me wonder how these other experts treat their co-workers and clients, if they berate them at every opportunity it is no wonder they have so much free time.
As for me, I have too much to do to worry overmuch about what tripe they are currently dishing up, in fact, I plan not to respond to them any longer as I am reminded of an old country saying:
"It does no good to get down in the mud and wrestle with pigs, you can't win and the pigs enjoy it."
So I shall spend my time working for my clients, researching and documenting Oracle behaviors, tips and techniques and acquiring new skills. Perhaps if these other experts would spend as much energy on putting out new material as they do circling the same issues over and over we would all benefit.
Note to Oracle: Perhaps you should find more for your experts to do, they seem to be caught in a rut.
I have stated my opinions on the subjects of indexes, clustering factors and data dictionary tables. I see no need to reiterate them. I have recanted incorrect advice I have given in the past. It is time to move on. Aren't there more interesting topics? Or perhaps they find, rather like Pro Wrestling draws a number of viewers, a good bash fest draws in more readers. I guess that is what happens when there is no technical content they can present as their own.
Learning is an iterative process, and during that time mistakes can and will be made. However if every time someone makes a misstatement or an error we bash them about the head and shoulders and then remind them of their past mistakes at every opportunity, they will soon cease learning altogether. Makes me wonder how these other experts treat their co-workers and clients, if they berate them at every opportunity it is no wonder they have so much free time.
As for me, I have too much to do to worry overmuch about what tripe they are currently dishing up, in fact, I plan not to respond to them any longer as I am reminded of an old country saying:
"It does no good to get down in the mud and wrestle with pigs, you can't win and the pigs enjoy it."
So I shall spend my time working for my clients, researching and documenting Oracle behaviors, tips and techniques and acquiring new skills. Perhaps if these other experts would spend as much energy on putting out new material as they do circling the same issues over and over we would all benefit.
Saturday, April 16, 2005
Standing By
In several posts at various Oracle related forums I have been taken to task for standing by Don Burleson. In the past I was also taken to task for standing by others such as Rich Niemiec. I have been repeatedly asked why I don't attack, belittle or otherwise "take on" many other experts.
Well, first, I believe people are entitled to their opinions.
Second, both of the above I consider to be friends. Where I come from you stand by your friends in public. Now in private I may tell them they are incorrect and suggest they alter their viewpoints, postings or papers, but not in a public forum where it could humiliate or embarrass them.
Others seem to enjoy laying about with wild abandon when someone is mistaken, falling all over each other like the spider creatures eating their wounded in the remake of "Lost In Space". They seem to enjoy laying scorn and abuse on others. This behavior is counter productive and leads to outright fear on the part of many neophytes about writing papers, posting answers or helping anyone anywhere online.
Of course the very folks that attack with guns blazing seem most upset when you fight back, rather like a school yard bully. They expect you to roll over and show your soft spots like a cur giving into a stronger dog. Sorry, can't do that, never did it, won't do it.
I will admit mistakes, and correct them when possible. I have done this in the past and will do it in the future. However I am a strong believer in positive feedback being more beneficial than negative feedback. I rarely listen to feedback that begins something like "You worthless git, your book/paper/presentation/tip is all bloody trash". However, I always open to "Mike, the tip is interesting, but here is a problem with what you have said", I may argue a bit, but I will listen and try to improve my knowledge and abilities. Be that as it may, you attack me in a public forum, I have no compunction about taking you to task over it, also in a public forum.
Anyway, enough rant.
Well, first, I believe people are entitled to their opinions.
Second, both of the above I consider to be friends. Where I come from you stand by your friends in public. Now in private I may tell them they are incorrect and suggest they alter their viewpoints, postings or papers, but not in a public forum where it could humiliate or embarrass them.
Others seem to enjoy laying about with wild abandon when someone is mistaken, falling all over each other like the spider creatures eating their wounded in the remake of "Lost In Space". They seem to enjoy laying scorn and abuse on others. This behavior is counter productive and leads to outright fear on the part of many neophytes about writing papers, posting answers or helping anyone anywhere online.
Of course the very folks that attack with guns blazing seem most upset when you fight back, rather like a school yard bully. They expect you to roll over and show your soft spots like a cur giving into a stronger dog. Sorry, can't do that, never did it, won't do it.
I will admit mistakes, and correct them when possible. I have done this in the past and will do it in the future. However I am a strong believer in positive feedback being more beneficial than negative feedback. I rarely listen to feedback that begins something like "You worthless git, your book/paper/presentation/tip is all bloody trash". However, I always open to "Mike, the tip is interesting, but here is a problem with what you have said", I may argue a bit, but I will listen and try to improve my knowledge and abilities. Be that as it may, you attack me in a public forum, I have no compunction about taking you to task over it, also in a public forum.
Anyway, enough rant.
Wednesday, April 13, 2005
Going Solid
(Note: This is a blog on a specific technical topic, solid state disk drives, any responses not germane to this topic will be deleted.)
Back in my days as a Nuclear Machinest Mate/ELT on board submarines in the USN, there was a condition known as "going solid" which referred to a controlled process where by the bubble of steam in the reactor coolant loop pressurizer was slowly compressed to force it back into water thus making the entire reactor loop solid with water. Under controlled conditions this was done for various reasons, if it happened by accident it was not good as you would have lost pressure control for the reactor cooling loop. So going solid in those days was both good (if done as a controlled exercise) and possibly very bad (if allowed to happen accidentally.) But that is not what I am referring to in this blog as going solid.
What I am referring to is the new trend (well, actually it has been around since the 90's) to move databases to solid state drives. In almost all cases this form of going solid leads to measurable performance improvements by elimination of the various latencies involved with the standard computer disk drive assemblies. Of course the removal of disk rotational and arm latencies is just one of the things that solid state drives bring to the table, the other is access to your data at near-memory speeds.
What solid state drives mean to an application is that if your application is currently suffering from IO problems some if not all of them are relieved. However, the benefits are a bit lop sided depending on the predominant type of IO wait your system is seeing. If your IO waits are due to contention during the retrieval of information (SELECT statements) then you can expect a dramatic increase in performance. In tests against standard disk arrays using the TPC-H benchmark I was able to achieve a 176 times performance increase for primarily retrieval based transactions. For what I refer to as IUD transactions (INSERT, UPDATE and DELETE) only a 30-60% performance improvement was shown.
Remember that retrieval requires no additional processing once the data location is returned from the search process, while IUD involves data verification via indexes, constraints and other internal processes that tend to slow down the process thus reducing the performance gains. Does solid state disk (SSD) technology eliminate waits? Of course not, what it does is reduce their duration. For example, looking at load times:
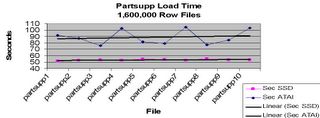
Load Graph Using SSD
You can from the graph that load times for standard disks was on the average about 30% slower than the load times for an equivalent SSD drive array.
However looking at query response time, we see an entirely different picture:
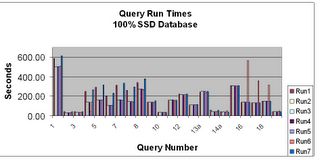
SSD Queries
When we compare the SSD times with the same queries, same OS settings and same layout on standard drives, we see a dramatic difference (notice the scale on this next graph is logarithmic, not linear):
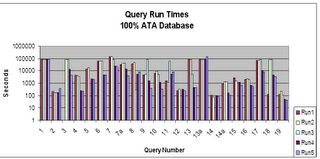
ATA Queries
The second graph really drives home the point, I had to make it logarithmic because of the great differences in time duration for the various queries when going to disks. What required a couple of hours (running the 20+ base queries) on SSD required 3 days on the average for the ATA drives.
Of course we don't remove the IO waits by using SSD, their duration is simply reduced to the point they are not a big factor anymore. Of course, for scalability and such you still will need to tune SQL.
Some how, I see going solid in our future.
For a complete copy of the testing look at:
http://www.rampant-books.com/book_2005_1_ssd.htm
For the latest in Solid State Drives look at:
http://www.texmemsys.com/
Back in my days as a Nuclear Machinest Mate/ELT on board submarines in the USN, there was a condition known as "going solid" which referred to a controlled process where by the bubble of steam in the reactor coolant loop pressurizer was slowly compressed to force it back into water thus making the entire reactor loop solid with water. Under controlled conditions this was done for various reasons, if it happened by accident it was not good as you would have lost pressure control for the reactor cooling loop. So going solid in those days was both good (if done as a controlled exercise) and possibly very bad (if allowed to happen accidentally.) But that is not what I am referring to in this blog as going solid.
What I am referring to is the new trend (well, actually it has been around since the 90's) to move databases to solid state drives. In almost all cases this form of going solid leads to measurable performance improvements by elimination of the various latencies involved with the standard computer disk drive assemblies. Of course the removal of disk rotational and arm latencies is just one of the things that solid state drives bring to the table, the other is access to your data at near-memory speeds.
What solid state drives mean to an application is that if your application is currently suffering from IO problems some if not all of them are relieved. However, the benefits are a bit lop sided depending on the predominant type of IO wait your system is seeing. If your IO waits are due to contention during the retrieval of information (SELECT statements) then you can expect a dramatic increase in performance. In tests against standard disk arrays using the TPC-H benchmark I was able to achieve a 176 times performance increase for primarily retrieval based transactions. For what I refer to as IUD transactions (INSERT, UPDATE and DELETE) only a 30-60% performance improvement was shown.
Remember that retrieval requires no additional processing once the data location is returned from the search process, while IUD involves data verification via indexes, constraints and other internal processes that tend to slow down the process thus reducing the performance gains. Does solid state disk (SSD) technology eliminate waits? Of course not, what it does is reduce their duration. For example, looking at load times:
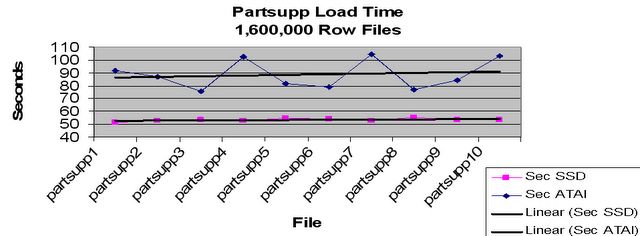
Load Graph Using SSD

You can from the graph that load times for standard disks was on the average about 30% slower than the load times for an equivalent SSD drive array.
However looking at query response time, we see an entirely different picture:

SSD Queries
When we compare the SSD times with the same queries, same OS settings and same layout on standard drives, we see a dramatic difference (notice the scale on this next graph is logarithmic, not linear):

ATA Queries
The second graph really drives home the point, I had to make it logarithmic because of the great differences in time duration for the various queries when going to disks. What required a couple of hours (running the 20+ base queries) on SSD required 3 days on the average for the ATA drives.
Of course we don't remove the IO waits by using SSD, their duration is simply reduced to the point they are not a big factor anymore. Of course, for scalability and such you still will need to tune SQL.
Some how, I see going solid in our future.
For a complete copy of the testing look at:
http://www.rampant-books.com/book_2005_1_ssd.htm
For the latest in Solid State Drives look at:
http://www.texmemsys.com/
Monday, April 11, 2005
Why No Comments
(Note: I have modified this blog, I stated in the first verison that the SQL execution plans didn't change, when actually we can't be sure, but from the bug reports and other statistics we gathered I had inferred this, sorry if I misled anyone.)
I have received a couple of rejoiners about not allowing comments on my last blog. I did this because I found that the people who were responding to other posts spent more time being negative than positive, more time tearing down then building up and more time to offer vindictive rather than constructive comments.
This entry, as the last, will not be allowing comments because I want it to stand by itself. When I make the next blog after this one, I will open it back up for comments. I indulged a bit of vindictive myself with my last blog, maybe it was justfied, maybe not. I just get tired of the self righteous experts out there that believe their way is the only way. I try to embrace whatever technologies will help my clients.
Let me explain how a typical client visit goes:
1. We get the call and issue a contract for the visit, let's say for a Database Healthcheck
2. The contract is assigned to a Senior DBA and it is determined to be either an onsite or remote job.
3. If onsite we go to the client and first review what problems they perceive they are having. This helps establish the parameters of the initial monitoring.
4. We then establish connectivity to the instance(s) to be monitored.
5. Using Oracle provided and self generated monitoring scripts the database is analyzed, usually for (not a complete list):
A. Wait events
B. IO spread and timing
C. Log events
D. Memory statistics and parameters
E. SQL usage
F. SQL statements which require too many resources
G. Access statistics if in 9i and 10g, otherwise major problem SQL is analyzed.
H. Parameter settings
6. The server is monitored for:
A. Disk IO
B. CPU usage statistics
C. Memory usage statistics
7. The system is reviewed for security and backup and recovery processes.
Usually one or more of the above causes the need for additional monitoring or analysis in a specific area, as time allows, this is done.
Using all of the above data, a detailed list of recommendations is prepared with actionable statements giving specific fixes and time estimates for the fixes. The "low hanging fruit" such as improvements to settings, server settings, addition of needed indexes, etc, are done, in a test environment if possible and the results analyzed (again if time and site procedures allow). The results of the analysis of the changes and the original data is used to prepare a final report with the actions suggested, actions taken, the results of the actions and the list of recommendations that still need to be implemented. Usually we include a whitepaper or two about the various techniques we may recommend.
We never go onsite and start issuing recommendations without analysis. The last time I saw this technique used was from Oracle support three days ago. Without looking at detailed statistics or analysis they suggested increasing the shared pool (even though all of it wasn't being used), increasing the database cache size (even though 30% of the buffers were free in V$BH), turn off MTS (we had already tried this and it made no difference) and several other Oracle "Silver Bullets", none of which made the slightest difference in the problem. It turned out the problem was that 10g has a default value of TRUE for the parameter _B_TREE_BITMAP_PLANS which, even though the application had been running for months, suddenly started making a difference. Note there were no bitmaps in the database other than those that Oracle had in their schemas. They offered no proofs, no explanations, just a sigh of relief that this Oracle Silver Bullet fixed the problem.
This is a classic example of why "simple", "repeatable" proofs can be hazardous. By all of the indications there was nothing wrong at the database level. No waits or events showed the problem, even plans for the SQL appaerently didn't change, since it was a systemic problem (any SQL causes the issue not just specific SQL) we didn't check plans before the fix was provided by Oracle support. Any SQL activity resulted in CPU spiking of up to 70-80%. However, the setting of this undocumented parameter had a profound effect on the optimizer and overall database performance. If an Oracle analyst hadn't "seen this before" and remembered this "Silver Bullet" the client would still be having problems. The troubled queries dropped form taking several minutes to 6 seconds.
When going from 7 to 8 to 8i to 9i to 10g Oracle has been notorious for resetting their undocumented parameters from true to false, false to true, adding new undocumented and documented parameters and of course varying the various number based parameters to get the right "mix". You have to understand this in order to trouble shoot Oracle performance problems. Even within the same release some of these change based on platform.
This is the point I am trying to make about single user, small database proofs, they are great for documenting Oracle behavior on single user, small databases. They would have been completely useless in this case.
Unless the "test" environment reached whatever trigger size caused the parameter to take precedence you could type in various proofs until your fingers were bloody and they would not have helped one iota.
In order to fully perceive a problem you have to look at it carefully, from both an atomic level and a holistic level or you will miss the tru solution in many cases. In others, you may know the solution (the application needs to be re-written) but it may be impossible to implement, either because of time or resource limits or because of support limits from vendors. In this case you must be prepared to treat symptoms to allow the database to function at an acceptable level.
That is the long and short of it.
I have received a couple of rejoiners about not allowing comments on my last blog. I did this because I found that the people who were responding to other posts spent more time being negative than positive, more time tearing down then building up and more time to offer vindictive rather than constructive comments.
This entry, as the last, will not be allowing comments because I want it to stand by itself. When I make the next blog after this one, I will open it back up for comments. I indulged a bit of vindictive myself with my last blog, maybe it was justfied, maybe not. I just get tired of the self righteous experts out there that believe their way is the only way. I try to embrace whatever technologies will help my clients.
Let me explain how a typical client visit goes:
1. We get the call and issue a contract for the visit, let's say for a Database Healthcheck
2. The contract is assigned to a Senior DBA and it is determined to be either an onsite or remote job.
3. If onsite we go to the client and first review what problems they perceive they are having. This helps establish the parameters of the initial monitoring.
4. We then establish connectivity to the instance(s) to be monitored.
5. Using Oracle provided and self generated monitoring scripts the database is analyzed, usually for (not a complete list):
A. Wait events
B. IO spread and timing
C. Log events
D. Memory statistics and parameters
E. SQL usage
F. SQL statements which require too many resources
G. Access statistics if in 9i and 10g, otherwise major problem SQL is analyzed.
H. Parameter settings
6. The server is monitored for:
A. Disk IO
B. CPU usage statistics
C. Memory usage statistics
7. The system is reviewed for security and backup and recovery processes.
Usually one or more of the above causes the need for additional monitoring or analysis in a specific area, as time allows, this is done.
Using all of the above data, a detailed list of recommendations is prepared with actionable statements giving specific fixes and time estimates for the fixes. The "low hanging fruit" such as improvements to settings, server settings, addition of needed indexes, etc, are done, in a test environment if possible and the results analyzed (again if time and site procedures allow). The results of the analysis of the changes and the original data is used to prepare a final report with the actions suggested, actions taken, the results of the actions and the list of recommendations that still need to be implemented. Usually we include a whitepaper or two about the various techniques we may recommend.
We never go onsite and start issuing recommendations without analysis. The last time I saw this technique used was from Oracle support three days ago. Without looking at detailed statistics or analysis they suggested increasing the shared pool (even though all of it wasn't being used), increasing the database cache size (even though 30% of the buffers were free in V$BH), turn off MTS (we had already tried this and it made no difference) and several other Oracle "Silver Bullets", none of which made the slightest difference in the problem. It turned out the problem was that 10g has a default value of TRUE for the parameter _B_TREE_BITMAP_PLANS which, even though the application had been running for months, suddenly started making a difference. Note there were no bitmaps in the database other than those that Oracle had in their schemas. They offered no proofs, no explanations, just a sigh of relief that this Oracle Silver Bullet fixed the problem.
This is a classic example of why "simple", "repeatable" proofs can be hazardous. By all of the indications there was nothing wrong at the database level. No waits or events showed the problem, even plans for the SQL appaerently didn't change, since it was a systemic problem (any SQL causes the issue not just specific SQL) we didn't check plans before the fix was provided by Oracle support. Any SQL activity resulted in CPU spiking of up to 70-80%. However, the setting of this undocumented parameter had a profound effect on the optimizer and overall database performance. If an Oracle analyst hadn't "seen this before" and remembered this "Silver Bullet" the client would still be having problems. The troubled queries dropped form taking several minutes to 6 seconds.
When going from 7 to 8 to 8i to 9i to 10g Oracle has been notorious for resetting their undocumented parameters from true to false, false to true, adding new undocumented and documented parameters and of course varying the various number based parameters to get the right "mix". You have to understand this in order to trouble shoot Oracle performance problems. Even within the same release some of these change based on platform.
This is the point I am trying to make about single user, small database proofs, they are great for documenting Oracle behavior on single user, small databases. They would have been completely useless in this case.
Unless the "test" environment reached whatever trigger size caused the parameter to take precedence you could type in various proofs until your fingers were bloody and they would not have helped one iota.
In order to fully perceive a problem you have to look at it carefully, from both an atomic level and a holistic level or you will miss the tru solution in many cases. In others, you may know the solution (the application needs to be re-written) but it may be impossible to implement, either because of time or resource limits or because of support limits from vendors. In this case you must be prepared to treat symptoms to allow the database to function at an acceptable level.
That is the long and short of it.
In a Galaxy Far, Far Away...
I read with amusement many of the “experts” posts, both as comments here and at many other websites. In my mind I imagine a conversation between these experts and my typical client (note, SATIRE SWITCH ON (I have never been present at a conversation between these experts and a client))
Client: Welcome to Acme! We have been looking forward to your visit! We really have some problems we want help with!
Expert: Good, as you know I am an expert and am here to help.
Client: Ok, where do you want to setup? Do you need connection to the database?
Expert: The CIO office would be nice.
Client: Well, errr, we have this cubical we set up for you.
(Looking down their nose) Expert: If I must.
(Looking relieved) Client: Great, it is right over here.
Client: How do you want to start?
Expert: I will have to look at all you data, its relationships to each other and how you use it.
(Looking concerned)Client: I’ll have to get that approved. How long do you think it will take?
Expert: Not longer than 2-3 weeks tops.
Client: 2-3 Weeks! At your rate that’s (getting out calculator) $54,000.00!
Expert: I am an expert and work directly for XXX. Is there a problem? (looking intimidating)
Client: Well, we had hoped to get it sooner, I will see about getting approval.
Expert: After that I will need to study the physical relationships of your entire database, how all the indexes are built, how all the tables are configured, and do root cause analysis of all waits and events.
(Looking impressed) Client: Wow! How long will that take?
Expert: Oh, not long, maybe another 3 weeks if I work overtime.
(Looking really concerned now)Client: That would mean more than $108,000.00…
Expert: Do you want this database to perform or not?
Client: Of course we want it to perform, that is why we brought you in. There may be some issues though…
Expert: How so?
Client: According to HIPPA and SOX, we can’t grant you access to our data and we are running a third-part application and can’t touch the code.
(Picking up laptop case) Expert: Sorry, I can’t help you, what do you think I am? Burleson Consulting? I can’t be expected to tune without changing the code, I don’t believe in silver-bullets that can be applied globally and if I don’t completely understand your data, structures, indexes and tables I simply can’t make any recommendations. You’ll get my bill.
Client: What was that name you mentioned?
(SATIRE SWITCH OFF)
Client: Welcome to Acme! We have been looking forward to your visit! We really have some problems we want help with!
Expert: Good, as you know I am an expert and am here to help.
Client: Ok, where do you want to setup? Do you need connection to the database?
Expert: The CIO office would be nice.
Client: Well, errr, we have this cubical we set up for you.
(Looking down their nose) Expert: If I must.
(Looking relieved) Client: Great, it is right over here.
Client: How do you want to start?
Expert: I will have to look at all you data, its relationships to each other and how you use it.
(Looking concerned)Client: I’ll have to get that approved. How long do you think it will take?
Expert: Not longer than 2-3 weeks tops.
Client: 2-3 Weeks! At your rate that’s (getting out calculator) $54,000.00!
Expert: I am an expert and work directly for XXX. Is there a problem? (looking intimidating)
Client: Well, we had hoped to get it sooner, I will see about getting approval.
Expert: After that I will need to study the physical relationships of your entire database, how all the indexes are built, how all the tables are configured, and do root cause analysis of all waits and events.
(Looking impressed) Client: Wow! How long will that take?
Expert: Oh, not long, maybe another 3 weeks if I work overtime.
(Looking really concerned now)Client: That would mean more than $108,000.00…
Expert: Do you want this database to perform or not?
Client: Of course we want it to perform, that is why we brought you in. There may be some issues though…
Expert: How so?
Client: According to HIPPA and SOX, we can’t grant you access to our data and we are running a third-part application and can’t touch the code.
(Picking up laptop case) Expert: Sorry, I can’t help you, what do you think I am? Burleson Consulting? I can’t be expected to tune without changing the code, I don’t believe in silver-bullets that can be applied globally and if I don’t completely understand your data, structures, indexes and tables I simply can’t make any recommendations. You’ll get my bill.
Client: What was that name you mentioned?
(SATIRE SWITCH OFF)
Saturday, April 09, 2005
Rumor Control
It seems numerous rumors and comments are being posted in the comments sections about things I may have once said, but upon research found were incorrect and retracted. Let me reiterate:
1. I have not found a case were an index rebuild, without re-arrangement of columns or change to the index structure, changes the clustering factor. Any prior advice I gave (nearly 2 years ago or so) to the contrary is incorrect.
2. I completely understand that the multiple block size feature in Oracle has limitations. I recommend them where the limitations are not a factor. That I haven't written a multi-page report on this fact with several more pages of complex proof, simply to prove what others have already done and is well documented in Oracle documentation I apologize for, I simply don't have the time to waste reinventing wheels.
3. The simple rules I mentioned in previous posts referred to the rules for database physical, PL/SQL and SQL design that are put forth in many of the Oak Table books, Oracle Press books and Rampant Books. Unfortunately, people don't follow these rules, the rules were made after the applications were designed, the people bought third party solutions that never follow any rules (good or bad), the people can't/won't change the code or a myriad set of other reasons that the good practices are not put in place. This is the real-world I dwell in and have to deal with.
4. I have never claimed that my advice on rebuilding indexes only applied to bitmaps, never have, never will. There are several situations where rebuilding or coalescing of indexes is beneficial and when I see a need for it, I will recommend it.
5. Why have I not attacked Don Burleson. Well, why have Howard and Tom never attacked Oracle for the many stupid things Oracle has done in the design and implementation of the Oracle product? For Oracle’s handling of support issues? For Oracle supports use of their own set of silver bullets? Also, Don has not attacked me. I am not confrontational by nature, I tend to let others have their opinions. When I can, I take Don to task in private for things which may be inaccurate, it is up to Don to change if he agrees with me. If I don't agree with everything Don advises, well, that is my opinion. It is rather like the TV, if you don't like what is being said, switch to another channel.
6. As to my opinions about asktom, yes, there are many good things there, there are also bad things as with any public forum. My major problem is that while it is supported by Oracle Corp. and supposedly moderated, I see things there that violate Oracles rules of conduct and should not be allowed on a moderated site. The examples are in the article, you can go to those links and see for yourself. Tom is excellent at providing proofs for his environment. But he rarely states "This proof should only be taken for proof in a similar environment to mine, your mileage may differ" and the very neofites you fear Don's and my advice will mislead, will be just as easily misled by correct proofs for an improper environment.
I attempt to avoid name-calling, bashing of others, and in general clouding issues with emotion charged clap-trap. In specific cases I have fought back when attacked by others and will continue to do so.
Oracle users tend to be a vocal lot. If advice causes problems it is generally well shouted from the roof tops. I task you Howard in presenting these shouts, if you cannot then you are but another chicken little proclaiming the sky is falling.
Any advice, when used incorrectly or without consideration is bad advice. Anyone who blindly follows suggestions, no matter what the source, without testing it in a test environment, deserves what they get.
If an automotive expert suggested I put water in my gas tank, I would question that advice, not blindly follow it. Compared to virtually all auto experts I am a neophyte in that area but I know not to blindly follow advice. When I go to a Doctor, an area I am definitely not trained in, if the advice sounds absurd I go to a second Doctor for their advice. There is no shortage of advice on Oracle, a quick check of Metalink, OTN and Google will find a plethora of opinions, demos, and advice on virtually any facet of Oracle administration you can imagine.
As I have said before, I have real work to do, I need to consolidate a list of 32 findings into something that can be accomplished with maximum return in 5 days. Not 2 weeks, not a month of study and testing, 5 days. Again, this is the real world.
1. I have not found a case were an index rebuild, without re-arrangement of columns or change to the index structure, changes the clustering factor. Any prior advice I gave (nearly 2 years ago or so) to the contrary is incorrect.
2. I completely understand that the multiple block size feature in Oracle has limitations. I recommend them where the limitations are not a factor. That I haven't written a multi-page report on this fact with several more pages of complex proof, simply to prove what others have already done and is well documented in Oracle documentation I apologize for, I simply don't have the time to waste reinventing wheels.
3. The simple rules I mentioned in previous posts referred to the rules for database physical, PL/SQL and SQL design that are put forth in many of the Oak Table books, Oracle Press books and Rampant Books. Unfortunately, people don't follow these rules, the rules were made after the applications were designed, the people bought third party solutions that never follow any rules (good or bad), the people can't/won't change the code or a myriad set of other reasons that the good practices are not put in place. This is the real-world I dwell in and have to deal with.
4. I have never claimed that my advice on rebuilding indexes only applied to bitmaps, never have, never will. There are several situations where rebuilding or coalescing of indexes is beneficial and when I see a need for it, I will recommend it.
5. Why have I not attacked Don Burleson. Well, why have Howard and Tom never attacked Oracle for the many stupid things Oracle has done in the design and implementation of the Oracle product? For Oracle’s handling of support issues? For Oracle supports use of their own set of silver bullets? Also, Don has not attacked me. I am not confrontational by nature, I tend to let others have their opinions. When I can, I take Don to task in private for things which may be inaccurate, it is up to Don to change if he agrees with me. If I don't agree with everything Don advises, well, that is my opinion. It is rather like the TV, if you don't like what is being said, switch to another channel.
6. As to my opinions about asktom, yes, there are many good things there, there are also bad things as with any public forum. My major problem is that while it is supported by Oracle Corp. and supposedly moderated, I see things there that violate Oracles rules of conduct and should not be allowed on a moderated site. The examples are in the article, you can go to those links and see for yourself. Tom is excellent at providing proofs for his environment. But he rarely states "This proof should only be taken for proof in a similar environment to mine, your mileage may differ" and the very neofites you fear Don's and my advice will mislead, will be just as easily misled by correct proofs for an improper environment.
I attempt to avoid name-calling, bashing of others, and in general clouding issues with emotion charged clap-trap. In specific cases I have fought back when attacked by others and will continue to do so.
Oracle users tend to be a vocal lot. If advice causes problems it is generally well shouted from the roof tops. I task you Howard in presenting these shouts, if you cannot then you are but another chicken little proclaiming the sky is falling.
Any advice, when used incorrectly or without consideration is bad advice. Anyone who blindly follows suggestions, no matter what the source, without testing it in a test environment, deserves what they get.
If an automotive expert suggested I put water in my gas tank, I would question that advice, not blindly follow it. Compared to virtually all auto experts I am a neophyte in that area but I know not to blindly follow advice. When I go to a Doctor, an area I am definitely not trained in, if the advice sounds absurd I go to a second Doctor for their advice. There is no shortage of advice on Oracle, a quick check of Metalink, OTN and Google will find a plethora of opinions, demos, and advice on virtually any facet of Oracle administration you can imagine.
As I have said before, I have real work to do, I need to consolidate a list of 32 findings into something that can be accomplished with maximum return in 5 days. Not 2 weeks, not a month of study and testing, 5 days. Again, this is the real world.
Subscribe to:
Comments (Atom)
