Found an interesting bug in Oracle 10g Release 1 yesterday. While working with a MERGE command we got the following results:
SQL> select count(*) from indv_d;
COUNT(*)
----------
62579
SQL> merge into dw1.indv_d f
2 using
3 (select a.cwin, a.dob, nvl(a.ethn_cd,'NA') ethn_cd,
4 nvl(b.ethic_desc,' Not Available') ethic_desc, a.sex_cd, c.sex_desc, a.prm_lang_cd,
5 nvl(d.lang_name,' Not Available') lang_name
6 from hra1.indv a
7 left outer join cis0.rt_ethic b
8 on a.ethn_cd = b.ethic_cd
9 left outer join cis0.rt_sex c
10 on a.sex_cd = c.sex_cd
11 left outer join cis0.rt_lang d
12 on a.prm_lang_cd = d.lang_cd
13 order by a.cwin
14 ) e
15 on
16 (
17 get_sign(e.cwinto_char(trunc(e.dob))e.ethn_cde.ethic_desce.sex_cd
18 e.sex_desce.prm_lang_cde.lang_name)
=
get_sign(f.cwinto_char(trunc(f.dob))f.ethn_cdf.ethic_descf.sex_cd
f.sex_descf.prm_lang_cdf.lang_name)
19 20 21 22 )
23 when not matched
24 then insert
25 (cwin, dob, ethn_cd,
26 ethic_desc, sex_cd, sex_desc, prm_lang_cd,
27 lang_name, indv_d_as_of)
28 values(e.cwin, e.dob, e.ethn_cd,
29 e.ethic_desc, e.sex_cd, e.sex_desc, e.prm_lang_cd,
30 e.lang_name, to_date('31-may-2005'))
31 ;
3179 rows merged.
SQL> select count(*) from indv_d;
COUNT(*)
----------
62579
SQL> select distinct indv_d_as_of, count(*)
2 from indv_d
3 group by indv_d_as_of;
INDV_D_AS COUNT(*)
--------- ----------
30-APR-05 62579
SQL> commit;
Commit complete.
Hmm…not quite what we expected….let’s do that again…
SQL> merge into dw1.indv_d f
2 using
3 (select a.cwin, a.dob, nvl(a.ethn_cd,'NA') ethn_cd,
4 nvl(b.ethic_desc,' Not Available') ethic_desc, a.sex_cd, c.sex_desc, a.prm_lang_cd,
5 nvl(d.lang_name,' Not Available') lang_name
6 from hra1.indv a
7 left outer join cis0.rt_ethic b
8 on a.ethn_cd = b.ethic_cd
9 left outer join cis0.rt_sex c
10 on a.sex_cd = c.sex_cd
11 left outer join cis0.rt_lang d
12 on a.prm_lang_cd = d.lang_cd
13 order by a.cwin
14 ) e
15 on
16 (
17 get_sign(e.cwinto_char(trunc(e.dob))e.ethn_cde.ethic_desce.sex_cd
18 e.sex_desce.prm_lang_cde.lang_name)
19 =
20 get_sign(f.cwinto_char(trunc(f.dob))f.ethn_cdf.ethic_descf.sex_cd
21 f.sex_descf.prm_lang_cdf.lang_name)
22 )
23 when not matched
24 then insert
25 (cwin, dob, ethn_cd,
26 ethic_desc, sex_cd, sex_desc, prm_lang_cd,
27 lang_name, indv_d_as_of)
28 values(e.cwin, e.dob, e.ethn_cd,
29 e.ethic_desc, e.sex_cd, e.sex_desc, e.prm_lang_cd,
30 e.lang_name, to_date('31-may-2005'))
31 ;
0 rows merged.
SQL> select count(*) from indv_d;
COUNT(*)
----------
62579
So, something happened to make it so that the source and target of the merge are no longer out of sync, but the good old standby “SELECT COUNT(*)” doesn’t seem to be working…let’s look at some additional queries and see what happens…
SQL> select count(*)
2 from hra1.indv a
3 left outer join cis0.rt_ethic b
4 on a.ethn_cd = b.ethic_cd
5 left outer join cis0.rt_sex c
6 on a.sex_cd = c.sex_cd
7 left outer join cis0.rt_lang d
8 on a.prm_lang_cd = d.lang_cd
9 order by a.cwin;
COUNT(*)
----------
64570
SQL> select (64570-62579) from dual;
(64570-62579)
-------------
1991
Hmm…seems we have a slight discrepancy here…let’ do some further investigation.
SQL> select distinct scn_to_timestamp(ora_rowscn), count(*)
2 from indv_d
3* group by scn_to_timestamp(ora_rowscn)
SQL> /
SCN_TO_TIMESTAMP(ORA_ROWSCN) COUNT(*)
------------------------------------------- --------
27-JUN-05 01.28.57.000000000 PM 2354
27-JUN-05 01.29.00.000000000 PM 12518
27-JUN-05 01.29.03.000000000 PM 7117
27-JUN-05 01.29.06.000000000 PM 8062
27-JUN-05 01.29.09.000000000 PM 7329
27-JUN-05 01.29.12.000000000 PM 7119
27-JUN-05 01.29.15.000000000 PM 7471
27-JUN-05 01.29.18.000000000 PM 7522
27-JUN-05 01.29.21.000000000 PM 2996
27-JUN-05 02.54.22.000000000 PM 3270
10 rows selected.
The total of the SCN counts above is 65758, so obviously something is hooky with the COUNT(*) process.
A check of the explain plan for the COUNT(*) (sorry, I didn’t get a capture of that, it was done in PL/SQL Developer) shows the COUNT(*) is using one of our bitmap indexes to resolve the count, which makes sense as the COUNT(*) has been optimized to use the lowest cost path and since bitmaps also index NULL values, it should be quickest. However, a quick metalink check (armed with the proper search criteria now (bitmap count(*)) brings up the following:
BUG: 4243687
Problem statement: COUNT(*) WRONG RESULTS WITH MERGE INSERT AND BITMAP INDEXES
Which goes on to explain:
While inserting a record with the merge insert, maintenance of bitmap indexes is not done.
Just a bit of an annoyance.
So be careful out there in 10g release 1 when using bitmaps and merge based inserts as this is not scheduled to be fixed until Release 2. Always drop the bitmap indexes before a merge insert and rebuild the bitmap indexes after your merge completes.
When we dropped the bitmap indexes we got the proper results and we also got the proper counts after rebuilding them.
From somewhere in coastal California, this is Mike Ault signing off…
Wednesday, June 29, 2005
Monday, June 13, 2005
Using Extended Memory in RedHat
In order to move above the 1.7-2.7 gig limit on SGA size for 32 bit Linux, many sites look at using the PAE capability with the shm or ramfs file system to utilize up to 62 gigabytes of memory for db block buffers. This is accomplished by using a 36 rather than a 32 bit addressing for the memory area and mapping the extended memory through the PAE (Page Address Extensions) to the configured memory file system. If upgrade to 64 bit CPUs and Linux is not an option, then this is a viable option. It is easy to accomplish:
1. Use the hugemem kernel in Linux RedHat 3.0 AS enterprise version.
2. Set up the shm file system or the ramfs filesystem to the size you want the upper memory for Oracle, plus about 10% or so.
3. Set use_indirect_data_buffers to true
For example:
· Mount the shmfs file system as root using command:
% mount -t shm shmfs -o nr_blocks=8388608 /dev/shm
· Set the shmmax parameter to half of RAM size
$ echo 3000000000 >/proc/sys/kernel/shmmax
· Set the init.ora parameter use_indirect_data_buffers=true
· Startup oracle.
However there are catches.
In recent testing it was found that unless the size of the memory used in the PAE extended memory configuration exceeded twice that available in the base 4 gigabytes, little was gained. However, the testing performed may not have been large enough to truly test the memory configuration. The test consisted of replay of a trace file through a testing tool to simulate multiple users performing statements. During this testing it was found that unless the memory is to be set at twice to three times the amount available in the base configuration using the PAE extensions may not be advisable.
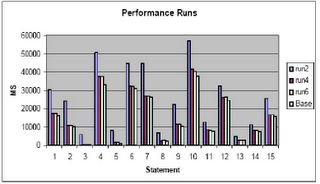
Memory Testing
In this chart I show:
Base Run: Run with 300 megabytes in lower memory
Run2: Run with 300 megabytes in upper memory
Run4: Run with 800 megabytes in upper memory
Run6: Run with 1200 megabytes in upper memory
In my opinion do not implement PAE unless larger memory sizes must be implemented than can be handled by the normal 4 gigabytes of lower memory. Unless you can double the available lower memory, that is, for a 1.7 gigabyte lower db_cache_size, to get similar performance, you must implement nearly a 3.4 gigabyte upper memory cache, you may not see a benefit, in fact, your performance may suffer. As can be seen from a comparison of the base run (300 megabytes lower memory) to run2 (run1 was to establish base load of the cache) performance actually decreased by 68% overall!
As you can see, even with 1200 megabytes in upper memory we still don’t get equal to the performance of 300 megabytes in lower memory (performance is still 7% worse than the base run). I can only conjecture at this point that the test:
1. Only utilized around 300 megabytes of cache or less
2. Should have performed more IO and had more users
3. All of the above
4. Shows you get a diminishing return as you add upper memory.
I tend to believe it is a combination of 1,2 and 4. There may be addition parameter tuning that could be applied to achieve better results (setting of the AWE_MEMORY_WINDOW parameter away from the default of 512M). If anyone knows of any, post them and I will see if I can get the client to retest.
1. Use the hugemem kernel in Linux RedHat 3.0 AS enterprise version.
2. Set up the shm file system or the ramfs filesystem to the size you want the upper memory for Oracle, plus about 10% or so.
3. Set use_indirect_data_buffers to true
For example:
· Mount the shmfs file system as root using command:
% mount -t shm shmfs -o nr_blocks=8388608 /dev/shm
· Set the shmmax parameter to half of RAM size
$ echo 3000000000 >/proc/sys/kernel/shmmax
· Set the init.ora parameter use_indirect_data_buffers=true
· Startup oracle.
However there are catches.
In recent testing it was found that unless the size of the memory used in the PAE extended memory configuration exceeded twice that available in the base 4 gigabytes, little was gained. However, the testing performed may not have been large enough to truly test the memory configuration. The test consisted of replay of a trace file through a testing tool to simulate multiple users performing statements. During this testing it was found that unless the memory is to be set at twice to three times the amount available in the base configuration using the PAE extensions may not be advisable.

Memory Testing
In this chart I show:
Base Run: Run with 300 megabytes in lower memory
Run2: Run with 300 megabytes in upper memory
Run4: Run with 800 megabytes in upper memory
Run6: Run with 1200 megabytes in upper memory
In my opinion do not implement PAE unless larger memory sizes must be implemented than can be handled by the normal 4 gigabytes of lower memory. Unless you can double the available lower memory, that is, for a 1.7 gigabyte lower db_cache_size, to get similar performance, you must implement nearly a 3.4 gigabyte upper memory cache, you may not see a benefit, in fact, your performance may suffer. As can be seen from a comparison of the base run (300 megabytes lower memory) to run2 (run1 was to establish base load of the cache) performance actually decreased by 68% overall!
As you can see, even with 1200 megabytes in upper memory we still don’t get equal to the performance of 300 megabytes in lower memory (performance is still 7% worse than the base run). I can only conjecture at this point that the test:
1. Only utilized around 300 megabytes of cache or less
2. Should have performed more IO and had more users
3. All of the above
4. Shows you get a diminishing return as you add upper memory.
I tend to believe it is a combination of 1,2 and 4. There may be addition parameter tuning that could be applied to achieve better results (setting of the AWE_MEMORY_WINDOW parameter away from the default of 512M). If anyone knows of any, post them and I will see if I can get the client to retest.
Wednesday, June 01, 2005
Are READ-ONLY Tablespaces Faster?
In a recent online article it was claimed that read-only tablespaces performed better than read-write tablespaces for SELECT type transactions. As could be predicted many folks jumped up and down about this saying this was not true. I decided rather than do a knee jerk reaction as these folks have done I would do something radical, I would test the premise using an actual database.
For my test I selected a 2,545,000 row table in a tablespace that has been placed on a 7X1 disk RAID-5 array attached to a 3 Ghtz CPU Linux Redhat 3.4 based server running Oracle Enterprise Version 10.1.0.3. The query was chosen to force a full table scan against the table by calculating an average of a non-indexed numeric field.
The table structure was:
SQL> desc merged_patient_counts_ru
Name--------------------------------------Null?----Type
----------------------------------------- -------- ----------------
SOURCE---------------------------------------------VARCHAR2(10)
PATIENT_NAME---------------------------------------VARCHAR2(128)
DMIS-----------------------------------------------VARCHAR2(4)
MEPRS----------------------------------------------VARCHAR2(32)
DIVISION_NAME--------------------------------------VARCHAR2(30)
MONTH----------------------------------------------VARCHAR2(6)
ICD9-----------------------------------------------VARCHAR2(9)
ICD9_CODE_DIAGNOSIS--------------------------------VARCHAR2(30)
ENCOUNTER_ADMISSION_DATETIME-----------------------DATE
ENCOUNTER_DISCHARGE_DATETIME-----------------------DATE
APP_COUNT------------------------------------------NUMBER
ADMIT_COUNT----------------------------------------NUMBER
ER_COUNT-------------------------------------------NUMBER
The SELECT statement used for the test was:
SQL> SELECT avg(app_count) FROM MERGED_PATIENT_COUNTS_RU;
AVG(APP_COUNT)
--------------
86.4054172
The explain plan and statistics (identical for both READ WRITE and READ ONLY executions) was:
Elapsed: 00:00:01.52
Execution Plan
----------------------------------------------------------
0---SELECT STATEMENT Optimizer=ALL_ROWS (Cost=1102 Card=1 Bytes=3)
1 0--SORT (AGGREGATE)
2 1--PX COORDINATOR
3 2--PX SEND* (QC (RANDOM)) OF ':TQ10000' :Q1000
4 3--SORT* (AGGREGATE) :Q1000
5 4--PX BLOCK* (ITERATOR) (Cost=1102 Card=2545000 Bytes :Q1000 =7635000)
6 5--TABLE ACCESS* (FULL) OF 'MERGED_PATIENT_COUNTS_R :Q1000
U' (TABLE) (Cost=1102 Card=2545000 Bytes=7635000)
3 PARALLEL_TO_SERIAL
4 PARALLEL_COMBINED_WITH_PARENT
5 PARALLEL_COMBINED_WITH_CHILD
6 PARALLEL_COMBINED_WITH_PARENT
Statistics
----------------------------------------------------------
12----recursive calls
0-----db block gets
21024-consistent gets
19312-physical reads
0-----redo size
418---bytes sent via SQL*Net to client
512---bytes received via SQL*Net from client
2-----SQL*Net roundtrips to/from client
53----sorts (memory)
0-----sorts (disk)
1-----rows processed
The process used for testing was:
1. Set timing on
2. Set autotrace on
3. Gather explain plans and statistics for both READ WRITE and READ ONLY runs, allowing statistics to stabilize.
4. Set autotrace off
5. Set tablespace status to READ WRITE
6. Execute SELECT 15 times
7. Set tablespace status to READ ONLY
8. Execute SELECT 15 times
The results are shown in table 1.
Reading Read Only Read Write
1-------1.49------1.56
2-------1.45------1.49
3-------1.39------1.37
4-------1.45------1.5
5-------1.5-------1.55
6-------1.3-------1.46
7-------1.43------1.5
8-------1.42------1.46
9-------1.35------1.38
10------1.4-------1.43
11------1.47------1.5
12------1.49------1.46
13------1.44------1.33
14------1.43------1.47
15------1.45------1.56
Avg-----1.430667--1.468
Table 1: Results from Performance Test of READ-ONLY Tablespace
As can be seen from the table, the performance of the READ-ONLY tablespace was marginally better (1.4307 verses 1.468 seconds on the average) than the READ-WRITE tablespace.
Based on these results, the article was correct in the assertion that the performance of READ-ONLY tablespaces is better than that of READ-WRITE tablespaces for SELECT transactions. While the performance difference is only a couple of percent it is still a measurable affect.
For my test I selected a 2,545,000 row table in a tablespace that has been placed on a 7X1 disk RAID-5 array attached to a 3 Ghtz CPU Linux Redhat 3.4 based server running Oracle Enterprise Version 10.1.0.3. The query was chosen to force a full table scan against the table by calculating an average of a non-indexed numeric field.
The table structure was:
SQL> desc merged_patient_counts_ru
Name--------------------------------------Null?----Type
----------------------------------------- -------- ----------------
SOURCE---------------------------------------------VARCHAR2(10)
PATIENT_NAME---------------------------------------VARCHAR2(128)
DMIS-----------------------------------------------VARCHAR2(4)
MEPRS----------------------------------------------VARCHAR2(32)
DIVISION_NAME--------------------------------------VARCHAR2(30)
MONTH----------------------------------------------VARCHAR2(6)
ICD9-----------------------------------------------VARCHAR2(9)
ICD9_CODE_DIAGNOSIS--------------------------------VARCHAR2(30)
ENCOUNTER_ADMISSION_DATETIME-----------------------DATE
ENCOUNTER_DISCHARGE_DATETIME-----------------------DATE
APP_COUNT------------------------------------------NUMBER
ADMIT_COUNT----------------------------------------NUMBER
ER_COUNT-------------------------------------------NUMBER
The SELECT statement used for the test was:
SQL> SELECT avg(app_count) FROM MERGED_PATIENT_COUNTS_RU;
AVG(APP_COUNT)
--------------
86.4054172
The explain plan and statistics (identical for both READ WRITE and READ ONLY executions) was:
Elapsed: 00:00:01.52
Execution Plan
----------------------------------------------------------
0---SELECT STATEMENT Optimizer=ALL_ROWS (Cost=1102 Card=1 Bytes=3)
1 0--SORT (AGGREGATE)
2 1--PX COORDINATOR
3 2--PX SEND* (QC (RANDOM)) OF ':TQ10000' :Q1000
4 3--SORT* (AGGREGATE) :Q1000
5 4--PX BLOCK* (ITERATOR) (Cost=1102 Card=2545000 Bytes :Q1000 =7635000)
6 5--TABLE ACCESS* (FULL) OF 'MERGED_PATIENT_COUNTS_R :Q1000
U' (TABLE) (Cost=1102 Card=2545000 Bytes=7635000)
3 PARALLEL_TO_SERIAL
4 PARALLEL_COMBINED_WITH_PARENT
5 PARALLEL_COMBINED_WITH_CHILD
6 PARALLEL_COMBINED_WITH_PARENT
Statistics
----------------------------------------------------------
12----recursive calls
0-----db block gets
21024-consistent gets
19312-physical reads
0-----redo size
418---bytes sent via SQL*Net to client
512---bytes received via SQL*Net from client
2-----SQL*Net roundtrips to/from client
53----sorts (memory)
0-----sorts (disk)
1-----rows processed
The process used for testing was:
1. Set timing on
2. Set autotrace on
3. Gather explain plans and statistics for both READ WRITE and READ ONLY runs, allowing statistics to stabilize.
4. Set autotrace off
5. Set tablespace status to READ WRITE
6. Execute SELECT 15 times
7. Set tablespace status to READ ONLY
8. Execute SELECT 15 times
The results are shown in table 1.
Reading Read Only Read Write
1-------1.49------1.56
2-------1.45------1.49
3-------1.39------1.37
4-------1.45------1.5
5-------1.5-------1.55
6-------1.3-------1.46
7-------1.43------1.5
8-------1.42------1.46
9-------1.35------1.38
10------1.4-------1.43
11------1.47------1.5
12------1.49------1.46
13------1.44------1.33
14------1.43------1.47
15------1.45------1.56
Avg-----1.430667--1.468
Table 1: Results from Performance Test of READ-ONLY Tablespace
As can be seen from the table, the performance of the READ-ONLY tablespace was marginally better (1.4307 verses 1.468 seconds on the average) than the READ-WRITE tablespace.
Based on these results, the article was correct in the assertion that the performance of READ-ONLY tablespaces is better than that of READ-WRITE tablespaces for SELECT transactions. While the performance difference is only a couple of percent it is still a measurable affect.
Subscribe to:
Posts (Atom)
