I recently purchased a back inflate buoyancy compensator (BC), an Oceanic Flex QLR. A BC is a jacket or vest that contains an inflatable bladder used to offset the weight of equipment (usually the air in the tank on your back if you are properly weighted), the bladder can be mostly in front in the “wings” of the vest/jacket, or, mostly on the back plate area (usually surrounding the tank area) or a combination of both. As many advanced divers utilize a BC known as a back plate with wings (BP/W), which is essentially a steel back plate designed to hold either a single or double tank rig surrounded by an inflatable bladder that is completely on the back of the diver. The advantage of a BP/W is that the steel plate can be made of various thicknesses of steel to allow the back plate to eliminate the need for extra lead weight that most divers have to carry in order to become neutrally buoyant. In addition to the weight benefits of a BP/W they are less encumbering and work well with a dry suit.
The Oceanic model I purchased (used of course) is a vest style with a hard, single tank plastic back plate and an inflation bladder that surrounds it. All-in-all the new BC seems to weigh about 4 pounds more than my old Calypso jacket style that utilized flotation bladders that surrounded you. This last weekend I decided to dive the new BC for the first time.
About an hour’s drive from the house is the Dive Haven Quarry in White, Georgia. The Dive Haven operation just started offering dive services to divers this year, previously we had to dive in Lake Lanier or go to quarries out of state in Tennessee or Alabama or lakes equally far away. In the Dive Haven quarry is an old diesel shovel/crane, it is about a 200 yard surface swim across the quarry then a 20-30 foot dive to the top of the crane arm. My dive buddies and I decided to try an underwater navigation at 20 feet deep (swimming underwater in full dive gear is easier than swimming on the surface.) Once at the crane I would do some photographs while they looked around, then, if air supply and time permitted we would look for the old car in about 20 feet of water nearby, after that we would once again do a 20 foot deep return dive utilizing compass and a sonar transponder I had placed on the dock to easily cross the 200 yards back to where we started.
One additional feature of the Oceanic BC is that it has an integrated weight system. In my old Calypso BC you needed a separate weight belt, which acted as a natural air dam to prevent excessive air in the dry suit from flowing to your feet, the new BC eliminated that. I loaded the Oceanic with 22 pounds of lead (this was what I had dove with using the Calypso and my dry suit) putting two 6 pound shot weights in the front, droppable weight pockets and two 3 pound shot weights in the non-releasable rear pockets. I then put two 2 pound weights in the BC pockets to bring me up to 22 pounds. Unfortunately I forgot to account for the additional 4 pounds of weight the Oceanic itself contributed to the overall weight of my gear and for the reduced profile (and hence reduced buoyancy) between the Oceanic and my Calypso. Looking back I figure I was over weighted by around 6 pounds.
As you can guess that 6 pounds made buoyancy control a nightmare. At the start of the dive you vent all of the air from your BC and dry suit and submerge, if you are properly weighted you will be slightly over weighted at the start of the dive because of the weight of the air in the tank or tanks, and, at the end of the dive just neutral with 500 pounds of air left. Unfortunately I sank like a stone and overshot the 20 foot target depth finally gaining control at 30 feet of depth. With the Calypso I was used to just giving a puff or two of air to halt a descent, of course being over weighted I had to give it quite a blast on top of the air I added to the dry suit to eliminate suit squeeze. Of course I over compensated then shot up to 15 feet or less before halting the rise. Finally I got the buoyancy set near right and we started for the crane.
It wasn’t long before I discovered one of the other joys being over weighted, my SAC rate (air consumption) was too high and the amount of effort I needed to expend to keep up with my dive partners was large. I was also now having to deal with air collecting in my legs and feet (officially called “having floaty feet”) if I put too much in to compensate for dry suit squeeze, it wasn’t a major problem, just one additional thing to deal with. Of course the fins I was using didn’t help matters much, they were older model stiff Scuba Pro’s, non-split, which means they were equivalent to strapping two boards on my feet. So between having to kick like a bee-stung mule and bouncing up and down like a cork because of the dicey buoyancy control I ended up doing the second half of the transit to the crane on the surface doing the back paddle (well, actually the back kick).
We got to the crane and I descended first. Visibility was only about 5 feet so with a descent rate of just under light speed due to being over weighted I nearly crashed into the crane arm having to push off from it as I rocketed past. Arresting my descent 10-15 feet deeper than I planned I then of course over compensated and shot past where I had wanted to stop and begin taking photographs. With reducing oscillations I finally managed to get where I wanted to and take a couple of shots. However, with my limited buoyancy control I was hesitant about going deeper to look over the cab and other parts of the crane since there were still cables and such that would just love to snare an unwary diver.
After taking the shots I felt safe doing I ascended and my dive partners then went down to have a look. By the time they returned we decided to forego the car and just return to the dock. We submerged to 20 feet and began the transit, again with me falling behind (got to replace those darn fins!) and I finished the last third of the transit on the surface once again as I was down to 500 pounds of air by that time.
On the second dive I removed 2 pounds of weight, I was still a bit over weighted but nearly as bad as before. We just puttered around at about 20-30 feet working on buoyancy control. Looks like I should pull at least another 2-4 pounds out to get where I need to be. Darn, looks like I might have to go diving again next weekend…
Monday, August 21, 2006
Thursday, August 03, 2006
A New Job
Well, on August 1, 2006 I started a new job. I am now an Oracle Specialist for Quest Software. The grind of 1099 consulting just got to be a bit much and the uncertainties of 1099 payments a bit wearing. So I will still be working head and shoulders deep in Oracle technology and still putting up Oracle tips and discoveries I just won’t be traveling as a consultant.
According to those folks who specialize in such things a job change can be as stressful as a death in the family. I prefer to think of it as a birth of new possibilities, adventures and opportunities. Much of the job will be learning what the Quest tools do verses those provided by Oracle and other Oracle tool vendors, a lot of experimenting, working with databases, writing white papers and tech sheets and just raw learning. All of the above I enjoy immensely when I have the time to do them and that is supposed to be built into this position.
For those who have a feature they just want to see added to Quest tools, something that just annoys them about an existing tool or any other constructive suggestions for the Oracle (or non-Oracle) quest toolset, send it in to me (mike.ault@quest.com) and I’ll see to it that it gets to the right person to take action.
I will miss some of the consulting work, the fun of helping folks get the most out of Oracle, the thrill of chasing down that illusive performance issue and the joy of teaching Oracle technologies such as real application clusters to folks in the field. However, there may still be a bit of that going on so it isn’t a complete sea change.
So it is time for the next chapter in my life and time to close the previous one. For those of you who I got to work with or for during the consulting period, thanks for the interesting assignments and work, and yes, I am still available by emails for questions. Hopefully in this next phase of work I will be able to help even more folks learn about Oracle and share even more Oracle knowledge than before.
Note: The opinions expressed on this web page are those of its author and not those of Quest Software, or its affiliates.
According to those folks who specialize in such things a job change can be as stressful as a death in the family. I prefer to think of it as a birth of new possibilities, adventures and opportunities. Much of the job will be learning what the Quest tools do verses those provided by Oracle and other Oracle tool vendors, a lot of experimenting, working with databases, writing white papers and tech sheets and just raw learning. All of the above I enjoy immensely when I have the time to do them and that is supposed to be built into this position.
For those who have a feature they just want to see added to Quest tools, something that just annoys them about an existing tool or any other constructive suggestions for the Oracle (or non-Oracle) quest toolset, send it in to me (mike.ault@quest.com) and I’ll see to it that it gets to the right person to take action.
I will miss some of the consulting work, the fun of helping folks get the most out of Oracle, the thrill of chasing down that illusive performance issue and the joy of teaching Oracle technologies such as real application clusters to folks in the field. However, there may still be a bit of that going on so it isn’t a complete sea change.
So it is time for the next chapter in my life and time to close the previous one. For those of you who I got to work with or for during the consulting period, thanks for the interesting assignments and work, and yes, I am still available by emails for questions. Hopefully in this next phase of work I will be able to help even more folks learn about Oracle and share even more Oracle knowledge than before.
Note: The opinions expressed on this web page are those of its author and not those of Quest Software, or its affiliates.
Tuesday, July 18, 2006
Cancun Vacation
Well, I am back from vacation. 8 days of no technology (well..other than digital cameras and a Sony picture vault mini-disk photo storage device.) I enjoyed Cancun and got to do several dives while I was there (six in all) of varying levels of difficulty. I dove my first two-tank dive concurrently with my wife and son-in-laws resort certification single tank dive. A double tank dive means two-one tank dives with a short interval on the surface between them. A resort certification is a 1-2 hour introduction to scuba with a pool session to help master basic skills and usually followed by a single tank “real” dive to no more than 30-40 feet of depth.
The first two-tank dive was a little bit of a disappointment due to the damage caused the reef from the large storms last year, much of the coral was showing signs of bleaching and there were many broken coral bits lying around. Usually the sea fans have a healthy purple color to them, the ones on the first dives were brown and looked rather ragged. There were lots of small juvenile fish, but not many large, mature fish. This first dive was on the Cancun side. We saw no rays, moray eels or other “staples” of a typical dive in the Caribbean.
The second two-tank dive was on the Cozumel side and I did it with my wife and son-in-law, which of course meant I couldn’t do the more advanced wall (deep) dive but had to stick to the shallow divemaster/instructor led dives. The coral looked healthier and there were more mature fish to be seen, but it was still not as good as I remembered from before the storms of a year ago. The highlight was a small octopus that we caught a glimpse of who was sleeping inside a coral formation (octopus are nocturnal by nature and sleep for the most part during the day.) The divemaster also showed my wife one of the small long-legged shrimp and let her hold it.
On the third two-tank dive I got to go on an advanced wreck/drift dive. The first dive was to about 80 feet deep on the C-58, the General Anaya, a sunken mine sweeper. The wreck had been a single site before the two large storms of 2005, but the first storm twisted the wreck in half and the second moved the bow about 100 yards away from the stern were it lays on its side with the bow now facing the same direction as the stern. On the stern section we did a swim through. As we swum though the upper structure (we didn’t do a penetration, we were in sight of an externally sun lit exit at all times) I couldn’t help but think back to the USS Haleakala, AE25, the first ship I was posted to when I was in the Navy. Although the two ships were totally different in purpose and design, the internal corridors where eerily similar, especially when we came upon a ladder (a set of steps) going up to an upper level and I noticed that they were identical in construction to those I used hundreds of times on the Haleakala.
Once we were done with the swim-through we followed the divemaster to the bow section. In station over the top of the bow were about a dozen greater barracudas. Since the bow was laying on its port (left) side, we didn’t do a swim-through (it also looked pretty ragged from being rolled/slammed along the bottom by the storm) we swam around the torn section behind it (to the topside, the keel was pointing back toward the stern section) and swam up to the bow sprint. We could see the current whipping material past, but we were shielded from it by the wreck, I was relieved when we retraced our path going behind the wreck instead of trying to swim across the current. However, this relief was short lived.
Once we got back to the section of the hull where it had been torn in half, we pointed into the current and started the swim to a reef that was several hundred yards away (at least it seemed that far in the current) we were moving on a diagonal to the current so we weren’t directly fighting it, but it was a bit of a workout for a 50 year old. We got to the reef structure and immediately saw a small sea turtle (about 2-3 foot shell size) who allowed us to photograph it and then nonchalantly swam away. We also saw a batfish (who uses two large, fleshy looking fins located on its top and bottom sides to move through the water) and a small nurse shark. This was the healthiest reef ( at 50 feet deep or so) with the largest fish and best looking coral. At one point we came up over a coral head and in a current-protected area saw a school of thousands of yellow-striped grunts that allowed us to swim in amongst them showing little fear of us.
The second dive was a drift dive over a reef. Again, the coral on this dive (at about 50 feet) was in much better condition that at the other sites and there were more mature fish and healthy coral and sea fans.
Overall the dives were fair to good, however, I have to give AquaWorld some negative feedback, my son-in-laws primary stage on his regulator (the primary takes the 3000 PSI air in the tank and drops it down to 140 PSI to feed to the secondary stage that you breath through and the various fill hoses you may use for your equipment such as the BCD or a drysuit) gave out at 20 feet down and stopped giving air, even though his SPG (submergible pressure guage) indicated he had 500 PSI in his tank. This wouldn’t have been a real problem if the dive masters assistant had been where he should have been to provide a spare air (octo) but instead my son-in-law was basically by himself , luckily we were only in 20 feet of water at the time and he had just exhaled out all his breath, he basically did a free ascent to the surface, but I don’t think he remembered to try to blow out all the way up. Had he not just done a complete exhale, he might have severely injured himself from a lung over-expansion injury. Usually first (or primary) stage failure, especially of this type, is due to allowing saltwater to get into the first stage causing the corrosion of the components and possible buildup of salt crystals which can jam air pathways in the internals of the regulator. Once on the surface the regulator breathed OK and the tank indicate 1000 PSI (remember that the pressure gage hooks up through the first stage so anything that blocks the primary air intake port will affect the pressure gage and the primary stage.) My son-in-law also experienced dump valve failure on his rented BCD on his second dive, another failure that shows lack of proper equipment maintenance. Since he was only in 20-30 feet of water, again, it wasn’t a big issue, but had he been a more experienced, certified diver and the condition occurred at 80 or 90 feet down, it may have resulted in an uncontrolled ascent and possible DCS (decompression sickness) hit.
These types of problems are why I am a strong supporter of owning at least your own regulator and BCD where you know the stuff is maintained properly.
I watched the divemaster on one of my dives take my BCD/regulator assembly from the expended tank and place it on the full tank for my second dive. I went over to record the pressure for my log and when I turned on the tank valve, could hear the distinct hiss of a air leak through the o-ring seal of the tank, when he did the pressure check he appearently hadn’t heard it. I pointed this out and he removed my rig to replace the o-ring on the tank valve. While he went to get a new o-ring, he just left my regulator lying where it was in a splash area from the forward motion of the boat through the waves, with the dust cap off. The dust cap keeps dust and debris, as well as water, from entering the first stage. I went over and replaced the dust cap on the regulator myself. On another dive where I had let them rig the second tank, they had neglected to remove the masking tape they used to cover the tank valve opening and had just put my rig over the top of it, why it didn’t leak like a sieve I don’t know, if they did this all the time, it could also explain the failure of my son-in-laws regulator as sections of the masking tape would plug up the filter on the intake port.
We also took a sub-sea and snorkel tour with the entire group of us trooping over to Paradise Island. The sub-sea adventure is little more than a more sea-worthy version of the old Nautilus ride at Disneyland. My major complaint was that the seating was designed by the same folks who designed the windows for airplanes, if you where five foot tall it was perfect, otherwise it required you to crane your neck uncomfortably for the entire tour to see out. They also went too fast, I understand having to maintain steerage, but they seemed to rush it a bit. The snorkel tour which followed was more like the coral 500 race as the guide seemed more interested in getting finished with his part of it rather than allowing us a leisurely snorkel through the reef.
The best thing we did with Aquaworld was the fishing trip my son-in-law and I took with them. Of course of the 6 hour fishing trip, probably an hour and a half was spent getting out and back and another hour was spent watching the Captain and his Mates catch the bait. However, even though we only fished for 3 hours out of the 6, we (there were 5 of us on the charter) caught 25 amberjack with the smallest at a bout 10-15 pounds the largest at about 30) and two Rock fish (one at about 10 pounds the second at 30 pounds). Needless to say, had we had a complete 6 hours of just fishing, I probably wouldn’t have been able to raise my arms. I was a little disappointed to hear we couldn’t get any of the meat because of the warmth of the water causing certain types of poisonous algae to be present and certain parasites to be in the fish (he showed us some worms he had removed from one of the fish.) I can’t really imagine the water temps being that radically different (lower) in the months with “r”s in them that far south, but supposedly it was an issue. The Captain said they gave the fish to poor who would spend days preparing the meat to make it edible. With our catch we must have fed 10-15 families if what he said was the truth and I have no reason to doubt him.
We also did some shopping at the various markets, Usually you can get some really good bargains if you are willing to haggle a bit, but I noticed overall the prices where quite a bit higher than my visit there 2 years ago and higher than the prices in the Cabo San Lucas area last year.
So now it is back in the saddle. Hopefully next entry I will have some juicy Oracle tidbits for you.
Mike
The first two-tank dive was a little bit of a disappointment due to the damage caused the reef from the large storms last year, much of the coral was showing signs of bleaching and there were many broken coral bits lying around. Usually the sea fans have a healthy purple color to them, the ones on the first dives were brown and looked rather ragged. There were lots of small juvenile fish, but not many large, mature fish. This first dive was on the Cancun side. We saw no rays, moray eels or other “staples” of a typical dive in the Caribbean.
The second two-tank dive was on the Cozumel side and I did it with my wife and son-in-law, which of course meant I couldn’t do the more advanced wall (deep) dive but had to stick to the shallow divemaster/instructor led dives. The coral looked healthier and there were more mature fish to be seen, but it was still not as good as I remembered from before the storms of a year ago. The highlight was a small octopus that we caught a glimpse of who was sleeping inside a coral formation (octopus are nocturnal by nature and sleep for the most part during the day.) The divemaster also showed my wife one of the small long-legged shrimp and let her hold it.
On the third two-tank dive I got to go on an advanced wreck/drift dive. The first dive was to about 80 feet deep on the C-58, the General Anaya, a sunken mine sweeper. The wreck had been a single site before the two large storms of 2005, but the first storm twisted the wreck in half and the second moved the bow about 100 yards away from the stern were it lays on its side with the bow now facing the same direction as the stern. On the stern section we did a swim through. As we swum though the upper structure (we didn’t do a penetration, we were in sight of an externally sun lit exit at all times) I couldn’t help but think back to the USS Haleakala, AE25, the first ship I was posted to when I was in the Navy. Although the two ships were totally different in purpose and design, the internal corridors where eerily similar, especially when we came upon a ladder (a set of steps) going up to an upper level and I noticed that they were identical in construction to those I used hundreds of times on the Haleakala.
Once we were done with the swim-through we followed the divemaster to the bow section. In station over the top of the bow were about a dozen greater barracudas. Since the bow was laying on its port (left) side, we didn’t do a swim-through (it also looked pretty ragged from being rolled/slammed along the bottom by the storm) we swam around the torn section behind it (to the topside, the keel was pointing back toward the stern section) and swam up to the bow sprint. We could see the current whipping material past, but we were shielded from it by the wreck, I was relieved when we retraced our path going behind the wreck instead of trying to swim across the current. However, this relief was short lived.
Once we got back to the section of the hull where it had been torn in half, we pointed into the current and started the swim to a reef that was several hundred yards away (at least it seemed that far in the current) we were moving on a diagonal to the current so we weren’t directly fighting it, but it was a bit of a workout for a 50 year old. We got to the reef structure and immediately saw a small sea turtle (about 2-3 foot shell size) who allowed us to photograph it and then nonchalantly swam away. We also saw a batfish (who uses two large, fleshy looking fins located on its top and bottom sides to move through the water) and a small nurse shark. This was the healthiest reef ( at 50 feet deep or so) with the largest fish and best looking coral. At one point we came up over a coral head and in a current-protected area saw a school of thousands of yellow-striped grunts that allowed us to swim in amongst them showing little fear of us.
The second dive was a drift dive over a reef. Again, the coral on this dive (at about 50 feet) was in much better condition that at the other sites and there were more mature fish and healthy coral and sea fans.
Overall the dives were fair to good, however, I have to give AquaWorld some negative feedback, my son-in-laws primary stage on his regulator (the primary takes the 3000 PSI air in the tank and drops it down to 140 PSI to feed to the secondary stage that you breath through and the various fill hoses you may use for your equipment such as the BCD or a drysuit) gave out at 20 feet down and stopped giving air, even though his SPG (submergible pressure guage) indicated he had 500 PSI in his tank. This wouldn’t have been a real problem if the dive masters assistant had been where he should have been to provide a spare air (octo) but instead my son-in-law was basically by himself , luckily we were only in 20 feet of water at the time and he had just exhaled out all his breath, he basically did a free ascent to the surface, but I don’t think he remembered to try to blow out all the way up. Had he not just done a complete exhale, he might have severely injured himself from a lung over-expansion injury. Usually first (or primary) stage failure, especially of this type, is due to allowing saltwater to get into the first stage causing the corrosion of the components and possible buildup of salt crystals which can jam air pathways in the internals of the regulator. Once on the surface the regulator breathed OK and the tank indicate 1000 PSI (remember that the pressure gage hooks up through the first stage so anything that blocks the primary air intake port will affect the pressure gage and the primary stage.) My son-in-law also experienced dump valve failure on his rented BCD on his second dive, another failure that shows lack of proper equipment maintenance. Since he was only in 20-30 feet of water, again, it wasn’t a big issue, but had he been a more experienced, certified diver and the condition occurred at 80 or 90 feet down, it may have resulted in an uncontrolled ascent and possible DCS (decompression sickness) hit.
These types of problems are why I am a strong supporter of owning at least your own regulator and BCD where you know the stuff is maintained properly.
I watched the divemaster on one of my dives take my BCD/regulator assembly from the expended tank and place it on the full tank for my second dive. I went over to record the pressure for my log and when I turned on the tank valve, could hear the distinct hiss of a air leak through the o-ring seal of the tank, when he did the pressure check he appearently hadn’t heard it. I pointed this out and he removed my rig to replace the o-ring on the tank valve. While he went to get a new o-ring, he just left my regulator lying where it was in a splash area from the forward motion of the boat through the waves, with the dust cap off. The dust cap keeps dust and debris, as well as water, from entering the first stage. I went over and replaced the dust cap on the regulator myself. On another dive where I had let them rig the second tank, they had neglected to remove the masking tape they used to cover the tank valve opening and had just put my rig over the top of it, why it didn’t leak like a sieve I don’t know, if they did this all the time, it could also explain the failure of my son-in-laws regulator as sections of the masking tape would plug up the filter on the intake port.
We also took a sub-sea and snorkel tour with the entire group of us trooping over to Paradise Island. The sub-sea adventure is little more than a more sea-worthy version of the old Nautilus ride at Disneyland. My major complaint was that the seating was designed by the same folks who designed the windows for airplanes, if you where five foot tall it was perfect, otherwise it required you to crane your neck uncomfortably for the entire tour to see out. They also went too fast, I understand having to maintain steerage, but they seemed to rush it a bit. The snorkel tour which followed was more like the coral 500 race as the guide seemed more interested in getting finished with his part of it rather than allowing us a leisurely snorkel through the reef.
The best thing we did with Aquaworld was the fishing trip my son-in-law and I took with them. Of course of the 6 hour fishing trip, probably an hour and a half was spent getting out and back and another hour was spent watching the Captain and his Mates catch the bait. However, even though we only fished for 3 hours out of the 6, we (there were 5 of us on the charter) caught 25 amberjack with the smallest at a bout 10-15 pounds the largest at about 30) and two Rock fish (one at about 10 pounds the second at 30 pounds). Needless to say, had we had a complete 6 hours of just fishing, I probably wouldn’t have been able to raise my arms. I was a little disappointed to hear we couldn’t get any of the meat because of the warmth of the water causing certain types of poisonous algae to be present and certain parasites to be in the fish (he showed us some worms he had removed from one of the fish.) I can’t really imagine the water temps being that radically different (lower) in the months with “r”s in them that far south, but supposedly it was an issue. The Captain said they gave the fish to poor who would spend days preparing the meat to make it edible. With our catch we must have fed 10-15 families if what he said was the truth and I have no reason to doubt him.
We also did some shopping at the various markets, Usually you can get some really good bargains if you are willing to haggle a bit, but I noticed overall the prices where quite a bit higher than my visit there 2 years ago and higher than the prices in the Cabo San Lucas area last year.
So now it is back in the saddle. Hopefully next entry I will have some juicy Oracle tidbits for you.
Mike
Wednesday, July 05, 2006
Oracle Timestamp Math
Had in interesting query from a client today. They have been storing start and stop times from a process in Oracle TIMESTAMP format and now want to get milliseconds out of the difference between the two timestamps. Seems pretty easy right?
Ok, first we create a table with two TIMESTAMP columns and an index value:
SQL> select * from check_time
SQL> /
TIM_COL1 TIM_COL2 TIME_INDEX
---------------------------- ---------------------------- ----------
05-JUL-06 05.00.42.437000 PM 05-JUL-06 05.01.54.984000 PM 1
05-JUL-06 05.03.14.781000 PM 05-JUL-06 05.03.39.328000 PM 2
Now, if we were just using DATE we could subtract the dates and use the proper multiplier to convert the fractional return to the proper time unit. However when we subtract TIMESTAMPs:
SQL> select tim_col2-tim_col1 from check_time;
TIM_COL2-TIM_COL1
------------------------------------------------
+000000000 00:01:12.547000
+000000000 00:00:24.547000
We get a hideous time interval upon which you can’t do math:
SQL> select sum(tim_col2-tim_col1) from check_time;
select sum(tim_col2-tim_col1) from check_time
*
ERROR at line 1:
ORA-00932: inconsistent datatypes: expected NUMBER got INTERVAL
So what can be done?
In steps the new interval functions that allow extraction of timestamp components, such as DAY, HOUR, MINUTE and SECOND…but wait there is no MILLISECOND! Of course a short trip to the documentation shows that the SECOND has a fractional component that allows us to specify the number of decimals after the second thus giving us access to the milliseconds, even down to microseconds in the interval value, look here:
SQL> l
1* select sum(extract(second from tim_col2)-extract(second from tim_col1))*1000 from check_time
SQL> /
SUM(EXTRACT(SECONDFROMTIM_COL2)-EXTRACT(SECONDFROMTIM_COL1))
------------------------------------------------------------
37094
Well, that is more like it! So now we can get the milliseconds between and do the aggregation functions such as sum() and avg() on the results.
Ok, first we create a table with two TIMESTAMP columns and an index value:
SQL> select * from check_time
SQL> /
TIM_COL1 TIM_COL2 TIME_INDEX
---------------------------- ---------------------------- ----------
05-JUL-06 05.00.42.437000 PM 05-JUL-06 05.01.54.984000 PM 1
05-JUL-06 05.03.14.781000 PM 05-JUL-06 05.03.39.328000 PM 2
Now, if we were just using DATE we could subtract the dates and use the proper multiplier to convert the fractional return to the proper time unit. However when we subtract TIMESTAMPs:
SQL> select tim_col2-tim_col1 from check_time;
TIM_COL2-TIM_COL1
------------------------------------------------
+000000000 00:01:12.547000
+000000000 00:00:24.547000
We get a hideous time interval upon which you can’t do math:
SQL> select sum(tim_col2-tim_col1) from check_time;
select sum(tim_col2-tim_col1) from check_time
*
ERROR at line 1:
ORA-00932: inconsistent datatypes: expected NUMBER got INTERVAL
So what can be done?
In steps the new interval functions that allow extraction of timestamp components, such as DAY, HOUR, MINUTE and SECOND…but wait there is no MILLISECOND! Of course a short trip to the documentation shows that the SECOND has a fractional component that allows us to specify the number of decimals after the second thus giving us access to the milliseconds, even down to microseconds in the interval value, look here:
SQL> l
1* select sum(extract(second from tim_col2)-extract(second from tim_col1))*1000 from check_time
SQL> /
SUM(EXTRACT(SECONDFROMTIM_COL2)-EXTRACT(SECONDFROMTIM_COL1))
------------------------------------------------------------
37094
Well, that is more like it! So now we can get the milliseconds between and do the aggregation functions such as sum() and avg() on the results.
Saturday, July 01, 2006
Diving A Drysuit
I am sure almost everyone has heard of a wetsuit. A wetsuit is basically a skintight neoprene rubber suit that divers wear to shield them from heat loss. A wetsuit shields the diver from heat loss by controlling the amount of water that comes in contact with the diver, limiting it to just enough to allow the divers own warmth to keep the water warm. The thickness of the neoprene determines how cold the water outside the suit can be and the diver still be comfortable. About the maximum thickness is 7 mm (about ¼ inch) and that will protect a diver in water in the range of 50-60 degrees.
50 to 60 degrees you say, that doesn’t seem so cold…well…the water transfers heat at 20 times the rate that air does. At 50 to 60 degrees a person will go hypothermic in a matter of minutes without a proper exposure suit. At 70 degrees you can get hypothermia as well, it may take a bit longer.
Now, what if the water is colder than 50-60 degrees? You could go with thicker wetsuits but then your mobility will be greatly restricted. The answer is called a drysuit. As its name implies a drysuit has seals that eliminate all water movement, that is, no water gets in, hence its name, drysuit. A drysuit provides no insulation, the diver must wear essentially, “long underwear” that provides the needed insulation, keeping the diver warm.
I recently got to dive a drysuit, the one I purchased was a great deal from www.divetank.com. I highly recommend them by the way, I purchased a Bare Nex Gen 200Z 2006 drysuit, it is made from trilaminate material, very light weight, very flexible and very easy to don and remove. Divetank provided the suit, neoprene dive hood, fill hose and the bag to carry it all for less than $650.00, I needed it right away so I had to fork over a bit for the next day shipping, but considering most drysuits run greater than $1,200.00 this was an outstanding deal.
First I prepared the buoyancy control device (basically an inflatable vest), the regulator and the air tank. You do this first because if you put on the full suit before setting up the rest of your equipment you risk getting heat stroke or becoming dehydrated while doing the setup operations.
To prepare the suit for use, first you must be sure the seals (in this suit at neck and wrists) are properly trimmed, otherwise you could choke, trigger various physical problems, or cut off circulation. Most seals are either neoprene or lycra (rubber). The rubber seals are marked with rings that provide cutting guidelines. For my suit I had to remove 1 ring from the neck seal which I did by placing the neck seal over a scuba bottle and then carefully following the ring boundary with my dive knife (which is razor sharp.) The wrist seals fit without trimming. A hint (provided by a fellow diver), use mild baby shampoo as lubricant to allow your hands to slip easily into the seals. Also, before each dive, you treat the zipper seal with bees wax to help seal it.
Once the seals fit I put on my lycra dive skin, the fleece under suit (provided with the suit) rather like a fleece jogging suit, my dive socks, then donned the drysuit. Then, before pulling the neck seal over my head and sealing the suit up, I put on my neoprene over booties over the soft boots that were part of the drysuit. My suit is a rear entry suit meaning the sealing zipper is on the back. My suit has the zipper across the shoulders, requiring a second diver to help. My dive buddy closed the zipper and seated the zipper pull into the seal.
Next, you put on your weight belt if you are using one (some BCDs have built in weight pockets, and some drysuit divers prefer a weight harness instead of a weight belt) and then don your BCD/regulator/tank assembly. Since we were diving a quarry (Dive Haven, White Georgia) we carried the mask and fins down to the waters edge to put them on, however, don’t, as I did, drop your second fin into deep water while putting on your first, necessitating your dive buddy do a search and recovery operation!
I also just bought a new mask strap, it has the full neoprene pad on the back and rather than rubber or lycra straps, uses nylon straps. I had problems with mask flooding as a result until we made sure that the mask was properly tightened and that no neoprene from the dive hood was stuck under the edge of the mask seal. After the mask issue was dealt with the dive went without a hitch.
We then did several ascents and descents to allow me to get a handle on using the combination of the drysuit and BCD to control suit squeeze and buoyancy. One issue many new drysuit divers trained using PADI have is that the PADI material says to use the drysuit to control buoyancy. This is incorrect.
You see the drysuit has an attached fill line from the low-pressure side of the first stage regulator, this is supposed to be used to relieve what is known as suit squeeze. Suit squeeze is caused by the pressure of the external water pressing the suit up tight against your body, a short burst of air provides for a thin layer of air in the suit to eliminate this. However, the suit should not be used for buoyancy control! You still use the BCD just as with a wetsuit. The suit also has an outlet valve that controls how much air is retained in the suit, it ranges from all the way shut to all the way open and adjusts by clicks, we set mine to 4 clicks off closed.
Once I got at least a beginning understanding of this needed control (after 5 ascents/descents) we did a normal dive at about 30-40 feet (51 degrees) and let me report I was comfortable except for my hands, I forgot my 5mm gloves and only had my light weight reef gloves to wear for the dive.
Overall I enjoyed the dive, learned the fundamentals of drysuit diving and had a great day with the other members of the Lake Lanier Loonies (we are considered Loony because we dive Lake Lanier year round.) I am also looking forward to my next drysuit dive (probably on July 4th.)
50 to 60 degrees you say, that doesn’t seem so cold…well…the water transfers heat at 20 times the rate that air does. At 50 to 60 degrees a person will go hypothermic in a matter of minutes without a proper exposure suit. At 70 degrees you can get hypothermia as well, it may take a bit longer.
Now, what if the water is colder than 50-60 degrees? You could go with thicker wetsuits but then your mobility will be greatly restricted. The answer is called a drysuit. As its name implies a drysuit has seals that eliminate all water movement, that is, no water gets in, hence its name, drysuit. A drysuit provides no insulation, the diver must wear essentially, “long underwear” that provides the needed insulation, keeping the diver warm.
I recently got to dive a drysuit, the one I purchased was a great deal from www.divetank.com. I highly recommend them by the way, I purchased a Bare Nex Gen 200Z 2006 drysuit, it is made from trilaminate material, very light weight, very flexible and very easy to don and remove. Divetank provided the suit, neoprene dive hood, fill hose and the bag to carry it all for less than $650.00, I needed it right away so I had to fork over a bit for the next day shipping, but considering most drysuits run greater than $1,200.00 this was an outstanding deal.
First I prepared the buoyancy control device (basically an inflatable vest), the regulator and the air tank. You do this first because if you put on the full suit before setting up the rest of your equipment you risk getting heat stroke or becoming dehydrated while doing the setup operations.
To prepare the suit for use, first you must be sure the seals (in this suit at neck and wrists) are properly trimmed, otherwise you could choke, trigger various physical problems, or cut off circulation. Most seals are either neoprene or lycra (rubber). The rubber seals are marked with rings that provide cutting guidelines. For my suit I had to remove 1 ring from the neck seal which I did by placing the neck seal over a scuba bottle and then carefully following the ring boundary with my dive knife (which is razor sharp.) The wrist seals fit without trimming. A hint (provided by a fellow diver), use mild baby shampoo as lubricant to allow your hands to slip easily into the seals. Also, before each dive, you treat the zipper seal with bees wax to help seal it.
Once the seals fit I put on my lycra dive skin, the fleece under suit (provided with the suit) rather like a fleece jogging suit, my dive socks, then donned the drysuit. Then, before pulling the neck seal over my head and sealing the suit up, I put on my neoprene over booties over the soft boots that were part of the drysuit. My suit is a rear entry suit meaning the sealing zipper is on the back. My suit has the zipper across the shoulders, requiring a second diver to help. My dive buddy closed the zipper and seated the zipper pull into the seal.
Next, you put on your weight belt if you are using one (some BCDs have built in weight pockets, and some drysuit divers prefer a weight harness instead of a weight belt) and then don your BCD/regulator/tank assembly. Since we were diving a quarry (Dive Haven, White Georgia) we carried the mask and fins down to the waters edge to put them on, however, don’t, as I did, drop your second fin into deep water while putting on your first, necessitating your dive buddy do a search and recovery operation!
I also just bought a new mask strap, it has the full neoprene pad on the back and rather than rubber or lycra straps, uses nylon straps. I had problems with mask flooding as a result until we made sure that the mask was properly tightened and that no neoprene from the dive hood was stuck under the edge of the mask seal. After the mask issue was dealt with the dive went without a hitch.
We then did several ascents and descents to allow me to get a handle on using the combination of the drysuit and BCD to control suit squeeze and buoyancy. One issue many new drysuit divers trained using PADI have is that the PADI material says to use the drysuit to control buoyancy. This is incorrect.
You see the drysuit has an attached fill line from the low-pressure side of the first stage regulator, this is supposed to be used to relieve what is known as suit squeeze. Suit squeeze is caused by the pressure of the external water pressing the suit up tight against your body, a short burst of air provides for a thin layer of air in the suit to eliminate this. However, the suit should not be used for buoyancy control! You still use the BCD just as with a wetsuit. The suit also has an outlet valve that controls how much air is retained in the suit, it ranges from all the way shut to all the way open and adjusts by clicks, we set mine to 4 clicks off closed.
Once I got at least a beginning understanding of this needed control (after 5 ascents/descents) we did a normal dive at about 30-40 feet (51 degrees) and let me report I was comfortable except for my hands, I forgot my 5mm gloves and only had my light weight reef gloves to wear for the dive.
Overall I enjoyed the dive, learned the fundamentals of drysuit diving and had a great day with the other members of the Lake Lanier Loonies (we are considered Loony because we dive Lake Lanier year round.) I am also looking forward to my next drysuit dive (probably on July 4th.)
Tuesday, June 13, 2006
50 Years and Counting
Well, I had a milestone of sorts last week, I turned 50 years of age. Odd, I don’t remember it like it was 50 years, and I don’t feel (mentally at least) like it’s been that long. Of course since life expectancies keep increasing and mine is a long lived family I may not even be middle aged yet…
As a teenager just getting into the work world I dreamed of being an oceanographer, then that morphed into a physicist or nuclear scientist. I worked in the Navy (1973-1979) as a machinist mate which actually means I repaired machines (vice a machinery repairmen who did machining work) and, since I was on a nuclear submarine, did laboratory and health physics work. Health physics means taking radiation surveys, cleaning up spills of radioactive water and materials and things dealing with keeping the rest of the crew (and outside world) from getting contaminated by the reactor. As a chemist I was responsible for maintaining the chemical balance in the non-radioactive steam plant and in the radioactive reactor coolant to help reduce corrosion and monitored the coolant loop for levels of radioactive material.
So, I was a nuclear chemist and health physicist for a while, then got out of the Navy and concentrated on being a Nuclear Chemist (1980-1990). Essentially I followed recipes to test water samples. The most fun part of the job was gamma spectroscopy. Essentially a gamma spectrometer was a chunk of ultra pure germanium super cooled by liquid nitrogen with a 2000 DC volt charge across it. When gamma rays interacted with it they would be absorbed (a certain fraction of the time) and during this process electron-hole pairs would be formed, the charge differential would sweep the electrons to the charge collection system which would amplify the signal. Some other electronics would then convert this analog data into a digital signal and result would be a number that through various mathematical convolutions you could use to determine the energy level of the original gamma ray.
Of course any one sample from a nuclear reactor coolant loop could have dozens of radioactive elements in it, each giving off one or more gamma rays, plus the normal background radiation (which we mitigated with lead shields). So a given gamma ray spectrum from a sample could hold dozens of gamma ray energy lines. I have included an example below. These lines could lay virtually on top of each other. In the beginning of the nuclear age a sodium iodine detector (essentially a chunk of salt) was used and it would produce scintillations whose brightness would correspond to the energy of the incident gamma ray, however the peaks produced would be wide (20-30 Kev FWHM) and difficult to analyze. The peaks would be hand plotted then the areas under them computed on a slide-rule and it would take days to analyze a single sample. With the germanium detectors the peaks would be nice and crisp (1-2 Kev FWHM) so it would be easier to see the peaks. However, we used computers to do the analysis of the germanium spectrums and what had taken days now took 11 seconds.

Fission Product Spectrum (From: Gamma Ray Spectrum Catalog, 1974, Aerojet Nuclear, R.L. Heath)
The first article I got an award for was “Gamma Emitting Isotopes of Medical Origin in Sanitary Waste Samples”, a real page turner. Anyway when I started in the civilian nuclear field I did about 90 percent chemistry and 10 percent computers, by the end of the 10 years I worked in the civilian field I was doing 90 percent computers and 10 percent chemistry. I was working at Tennessee Valley Authority when Marvin Runyon ( unaffectionately called Marvin Runyaoff ) was brought in to clean up TVA. His clean up, due to union rules and contracts, consisted of firing (laid-off) all of the junior people (read, the ones with the new ideas, new concepts and new ways of doing things) and keeping the old timers ( status quo, keep things the way they are, let’s not types) since I only had 3 years of staff time, I was let go.
I determined that Nuclear power had limited upward mobility so taking a deep breath I leaped into the computer world. I had been working with the Informix and Ingres databases and had been the database administrator and developer for the VAX-VMS based systems in the Sequoyah Nuclear Training center, I saw an advertisement for an Oracle DBA job working with Aerojet on a NASA project so I sent in my resume. I was called in for an interview so I quickly picked up the book (at that time there was only one) on Oracle and read it on the flight to the interview. I believe I got the job because I was the only one who showed up for the interview. The job was in Iuka, Mississippi at the old Yellow Creek nuclear site, sold by TVA to the government to be the site for the factory building the replacement boosters for the space shuttle. I guess you could say that ultimately I owe my career in Oracle to the Challenger shuttle disaster since the Iuka plant was a direct result of that incident. I finally finished my degree in ’92 in computer science with Kennedy-Western University. I had over 140 credits from various classes and courses I had taken or CLEP’ed while I was in the Navy, but no clear concentration to give me a degree. I took that and a bit of life credit and some additional course work and parlayed that into a computer science degree.
Since then I have worked exclusively with the Oracle database system on VAX-VMS, HPUX, Sun Solaris, AIX, Linux, Windows (various) with Oracle versions 6.0.22 to 10.2.0.2. I have been to 14 countries, 20 States, two sets of Islands (The Canaries and Los Rochas Archeapeligo) given dozens of lectures and presentations, taught thousands of folks how to use, tune and maintain Oracle, and wrote 2 dozen books. I’ve even had a couple of fiction short stories published.
During this 50 years I also met and wed my wife of 32 (almost 33) years, Susan, had two wonderful daughters (Marie and Michelle) and come this October will be a Grandfather.
It has been quite a ride, this first half (third?) of my life. I have ridden and repaired (and steered) nuclear submarines, stood next to a nuclear reactor, flown in jet aircraft, sailed on surface ships and cruise liners, parasailed, driven bicycles, cars, motorcycles, trucks, boats learned to fish, hunt, scuba dive, dance, sing, play the guitar, play the dulcimer, work with wood, work with chemistry, and work with computers. I’ve watched my daughters be born, grow up, get married and now get to watch as they bring new life into the world. I’ve dealt with the death of loved ones, the horrors of the world, the joys of life. I’ve read well over 3000 books, attended 14 different schools from kindergarten to my college degree. I’ve learned a bit of tolerance, how to love and thankfully not too much how to hate, learned to love God and praise powers higher than myself.
I’m looking forward to what the next 50-100 years brings.
As a teenager just getting into the work world I dreamed of being an oceanographer, then that morphed into a physicist or nuclear scientist. I worked in the Navy (1973-1979) as a machinist mate which actually means I repaired machines (vice a machinery repairmen who did machining work) and, since I was on a nuclear submarine, did laboratory and health physics work. Health physics means taking radiation surveys, cleaning up spills of radioactive water and materials and things dealing with keeping the rest of the crew (and outside world) from getting contaminated by the reactor. As a chemist I was responsible for maintaining the chemical balance in the non-radioactive steam plant and in the radioactive reactor coolant to help reduce corrosion and monitored the coolant loop for levels of radioactive material.
So, I was a nuclear chemist and health physicist for a while, then got out of the Navy and concentrated on being a Nuclear Chemist (1980-1990). Essentially I followed recipes to test water samples. The most fun part of the job was gamma spectroscopy. Essentially a gamma spectrometer was a chunk of ultra pure germanium super cooled by liquid nitrogen with a 2000 DC volt charge across it. When gamma rays interacted with it they would be absorbed (a certain fraction of the time) and during this process electron-hole pairs would be formed, the charge differential would sweep the electrons to the charge collection system which would amplify the signal. Some other electronics would then convert this analog data into a digital signal and result would be a number that through various mathematical convolutions you could use to determine the energy level of the original gamma ray.
Of course any one sample from a nuclear reactor coolant loop could have dozens of radioactive elements in it, each giving off one or more gamma rays, plus the normal background radiation (which we mitigated with lead shields). So a given gamma ray spectrum from a sample could hold dozens of gamma ray energy lines. I have included an example below. These lines could lay virtually on top of each other. In the beginning of the nuclear age a sodium iodine detector (essentially a chunk of salt) was used and it would produce scintillations whose brightness would correspond to the energy of the incident gamma ray, however the peaks produced would be wide (20-30 Kev FWHM) and difficult to analyze. The peaks would be hand plotted then the areas under them computed on a slide-rule and it would take days to analyze a single sample. With the germanium detectors the peaks would be nice and crisp (1-2 Kev FWHM) so it would be easier to see the peaks. However, we used computers to do the analysis of the germanium spectrums and what had taken days now took 11 seconds.

Fission Product Spectrum (From: Gamma Ray Spectrum Catalog, 1974, Aerojet Nuclear, R.L. Heath)
The first article I got an award for was “Gamma Emitting Isotopes of Medical Origin in Sanitary Waste Samples”, a real page turner. Anyway when I started in the civilian nuclear field I did about 90 percent chemistry and 10 percent computers, by the end of the 10 years I worked in the civilian field I was doing 90 percent computers and 10 percent chemistry. I was working at Tennessee Valley Authority when Marvin Runyon ( unaffectionately called Marvin Runyaoff ) was brought in to clean up TVA. His clean up, due to union rules and contracts, consisted of firing (laid-off) all of the junior people (read, the ones with the new ideas, new concepts and new ways of doing things) and keeping the old timers ( status quo, keep things the way they are, let’s not types) since I only had 3 years of staff time, I was let go.
I determined that Nuclear power had limited upward mobility so taking a deep breath I leaped into the computer world. I had been working with the Informix and Ingres databases and had been the database administrator and developer for the VAX-VMS based systems in the Sequoyah Nuclear Training center, I saw an advertisement for an Oracle DBA job working with Aerojet on a NASA project so I sent in my resume. I was called in for an interview so I quickly picked up the book (at that time there was only one) on Oracle and read it on the flight to the interview. I believe I got the job because I was the only one who showed up for the interview. The job was in Iuka, Mississippi at the old Yellow Creek nuclear site, sold by TVA to the government to be the site for the factory building the replacement boosters for the space shuttle. I guess you could say that ultimately I owe my career in Oracle to the Challenger shuttle disaster since the Iuka plant was a direct result of that incident. I finally finished my degree in ’92 in computer science with Kennedy-Western University. I had over 140 credits from various classes and courses I had taken or CLEP’ed while I was in the Navy, but no clear concentration to give me a degree. I took that and a bit of life credit and some additional course work and parlayed that into a computer science degree.
Since then I have worked exclusively with the Oracle database system on VAX-VMS, HPUX, Sun Solaris, AIX, Linux, Windows (various) with Oracle versions 6.0.22 to 10.2.0.2. I have been to 14 countries, 20 States, two sets of Islands (The Canaries and Los Rochas Archeapeligo) given dozens of lectures and presentations, taught thousands of folks how to use, tune and maintain Oracle, and wrote 2 dozen books. I’ve even had a couple of fiction short stories published.
During this 50 years I also met and wed my wife of 32 (almost 33) years, Susan, had two wonderful daughters (Marie and Michelle) and come this October will be a Grandfather.
It has been quite a ride, this first half (third?) of my life. I have ridden and repaired (and steered) nuclear submarines, stood next to a nuclear reactor, flown in jet aircraft, sailed on surface ships and cruise liners, parasailed, driven bicycles, cars, motorcycles, trucks, boats learned to fish, hunt, scuba dive, dance, sing, play the guitar, play the dulcimer, work with wood, work with chemistry, and work with computers. I’ve watched my daughters be born, grow up, get married and now get to watch as they bring new life into the world. I’ve dealt with the death of loved ones, the horrors of the world, the joys of life. I’ve read well over 3000 books, attended 14 different schools from kindergarten to my college degree. I’ve learned a bit of tolerance, how to love and thankfully not too much how to hate, learned to love God and praise powers higher than myself.
I’m looking forward to what the next 50-100 years brings.
Tuesday, May 02, 2006
Time for a Change Part 2
In my previous post I made the outlandish (to some, notably foreign based readers) suggestion that the USA should start tying the cost of goods and services provided to oil producing countries to the cost of a barrel of crude oil purchased from that country.
For example the following countries derive a great deal of benefit from selling the USA oil:
Venezuela - Leader virtually destroyed the middle class, says he wants to model country after Cuba
Nigeria - Place were genocide is an established practice
Mexico - Believes the solution to their problems is to send them to USA
Iraq - Need I say more
Libya - Need I say more
Algeria - Another fun spot
If we were to turn this dependency on their oil into a dependency on our money we would have the leverage, add to that the amount of aid we provide several of these countries (whether from loans or charities) and we should not have issues with them. Instead they threaten us with a price increase and we back down, they refuse to help their own, and we step in, they commit genocide and we look away. Ties into the same idea that you give your wallet to a robber and let the principles of civilized behavior be damned. Let's all be a victim!
Yes, we also get a great deal of our Oil (at least by 2002 numbers) from Canada however, as far as I know Canada doesn't practice genocide, ship their poor to us, chop off various arms and legs of innocent villagers, threaten our other allies, threaten us with nuclear war, or have several civil wars going at a time. Another large source are the countries Saudi Arabia and Kuwait, and while I may not agree with their style of government, for the most part their people appear well kept, well fed and peaceful, do they have problems? Yes, but not like many other countries in that region. However, OPEC is OPEC, and if they choose to run with the OPEC herd, then if such a policy as I have stated were to go into effect, they could choose which side to be on.
I am not sure what the detractors would have us do...I guess just sit back and take it like always. Of course most are from other countries so it isn't any skin off their noses if we do. Many of them have governments which tack on huge taxes on their gas prices to pay for their free medical and other dole out programs so they have had high prices for years. I guess they just feel it was our turn.
What I would really like to see is the full development of a proper mass-transit infrastructure in the USA. However, this isn't going to spring up overnight. Many places are starting to do this, many need to. The high prices will force more conservation, so in the long haul they may be a good thing, however, increases of nearly 60% in a years time, when oil company profits are at an all time high, aren't.
Do I hate the countries that are doing this to the USA? No, I do not. I may detest their leaders and their leader's policies that have driven the countries to this horrible state but I am sure many of the people there are good, decent folks just trying to survive the follies of their governments (as we all do).
Do I want to see children starve? No, however, I am not responsible for their current or future state, their government is, until their governments are "shown the light" they will continue to starve regardless of what we do or don't do. In fact, by forcing their governments to take responsibility we will be saving more in the long term. I believe there is an old saying about "Give a man a fish and he will eat for a day, teach him to fish and he will never be hungry" we need to teach their governments to fish.
As to whether my Christianity is being used a a shield, no, it is not, I was using it to show my own discomfort at the feelings I am having. Yes, by a literal interpretation of the Christian teachings we should just roll over and take whatever is handed us, however, I am not a believer in the literal word-for-word blind following of any teaching. For one, there are many errors in translation in all testaments (Christian or otherwise), add to that deliberate shall I say "shadings" and you need to be very careful when reading for meaning. If we all followed the teachings to the letter, there would be no more Christians after this generation.
Remember, everyone pays the same for a barrel of oil, if your prices are high, look to your government and oil companies, as we in the USA need to look at ours. We should all be looking at ways to cut back. We need to look at oil not as gasoline, but as medicine, plastics, chemicals, things which in many ways are much more important than gasoline.
Yes, we need to look at hydrogen, electric, hybrid vehicles (which by the way I am looking at for a replacement of my current vehicles, when it makes economic sense to do so) and other ways of saving oil. I have been accumulating technologies to use to build an "off the grid" home (solar, wind, etc) and plan to do so as soon as I can, am I going to bankrupt my family and do it right now? No.
However, as worthy as conservation is for our consideration and implementation, that doesn't forgive price gouging, and other things that point to greed, not need, as the reason for price increases.
For example the following countries derive a great deal of benefit from selling the USA oil:
Venezuela - Leader virtually destroyed the middle class, says he wants to model country after Cuba
Nigeria - Place were genocide is an established practice
Mexico - Believes the solution to their problems is to send them to USA
Iraq - Need I say more
Libya - Need I say more
Algeria - Another fun spot
If we were to turn this dependency on their oil into a dependency on our money we would have the leverage, add to that the amount of aid we provide several of these countries (whether from loans or charities) and we should not have issues with them. Instead they threaten us with a price increase and we back down, they refuse to help their own, and we step in, they commit genocide and we look away. Ties into the same idea that you give your wallet to a robber and let the principles of civilized behavior be damned. Let's all be a victim!
Yes, we also get a great deal of our Oil (at least by 2002 numbers) from Canada however, as far as I know Canada doesn't practice genocide, ship their poor to us, chop off various arms and legs of innocent villagers, threaten our other allies, threaten us with nuclear war, or have several civil wars going at a time. Another large source are the countries Saudi Arabia and Kuwait, and while I may not agree with their style of government, for the most part their people appear well kept, well fed and peaceful, do they have problems? Yes, but not like many other countries in that region. However, OPEC is OPEC, and if they choose to run with the OPEC herd, then if such a policy as I have stated were to go into effect, they could choose which side to be on.
I am not sure what the detractors would have us do...I guess just sit back and take it like always. Of course most are from other countries so it isn't any skin off their noses if we do. Many of them have governments which tack on huge taxes on their gas prices to pay for their free medical and other dole out programs so they have had high prices for years. I guess they just feel it was our turn.
What I would really like to see is the full development of a proper mass-transit infrastructure in the USA. However, this isn't going to spring up overnight. Many places are starting to do this, many need to. The high prices will force more conservation, so in the long haul they may be a good thing, however, increases of nearly 60% in a years time, when oil company profits are at an all time high, aren't.
Do I hate the countries that are doing this to the USA? No, I do not. I may detest their leaders and their leader's policies that have driven the countries to this horrible state but I am sure many of the people there are good, decent folks just trying to survive the follies of their governments (as we all do).
Do I want to see children starve? No, however, I am not responsible for their current or future state, their government is, until their governments are "shown the light" they will continue to starve regardless of what we do or don't do. In fact, by forcing their governments to take responsibility we will be saving more in the long term. I believe there is an old saying about "Give a man a fish and he will eat for a day, teach him to fish and he will never be hungry" we need to teach their governments to fish.
As to whether my Christianity is being used a a shield, no, it is not, I was using it to show my own discomfort at the feelings I am having. Yes, by a literal interpretation of the Christian teachings we should just roll over and take whatever is handed us, however, I am not a believer in the literal word-for-word blind following of any teaching. For one, there are many errors in translation in all testaments (Christian or otherwise), add to that deliberate shall I say "shadings" and you need to be very careful when reading for meaning. If we all followed the teachings to the letter, there would be no more Christians after this generation.
Remember, everyone pays the same for a barrel of oil, if your prices are high, look to your government and oil companies, as we in the USA need to look at ours. We should all be looking at ways to cut back. We need to look at oil not as gasoline, but as medicine, plastics, chemicals, things which in many ways are much more important than gasoline.
Yes, we need to look at hydrogen, electric, hybrid vehicles (which by the way I am looking at for a replacement of my current vehicles, when it makes economic sense to do so) and other ways of saving oil. I have been accumulating technologies to use to build an "off the grid" home (solar, wind, etc) and plan to do so as soon as I can, am I going to bankrupt my family and do it right now? No.
However, as worthy as conservation is for our consideration and implementation, that doesn't forgive price gouging, and other things that point to greed, not need, as the reason for price increases.
Sunday, April 30, 2006
Time for a Change
So gas has gone up nearly double in less than year. Makes me wonder how much we have increased the cost of food we are selling overseas. I believe we need to tie the cost of a bushel of wheat, corn or other food stuff directly to the cost of a barrel of oil from the particular country we get the oil from. Gas goes up 10%, their cost for food goes up 10%.
It would be an interesting study to look at the average cost of a barrel of oil and tie it to the average cost at the pump. Maybe we can look closer to home for some of the problems as well. Make the cost of a gallon of gas be a ratio to the cost of a barrel of oil.
Let’s do that with all medical supplies as well. It is pretty bad when many times folks in countries hostile to us can get medicine cheaper than we can…from a US company!
Last time I checked most food can be converted to alcohol, sure some is more efficient (corn) but just about anything we can digest and has sugar in it can be digested by yeast to produce alcohol, cars will run on that, as the oil companies have been saying ad-nauseam. As far as I know, it is rather more difficult to convert oil to food. Seems we have a bigger stick, not much grows in the desert, especially when there is no food to feed the workers.
Of course, we would have to harden ourselves to the site of hungry and starving children, that will be the first weapon they would use, pictures of their children. We would have to stifle the bleeding hearts out there. Perhaps if we stopped feeding the world for a loss they would start taking better care of their people. Most countries are only three-square meals away from revolution.
Tie it to the cost of electronics and other high tech items as well. Put a large tariff on technical talent, most of the oil wells out there wouldn’t be running without American know-how.
It is time for America to get tough. Time for us to harden our hearts a bit. As a Christian this hurts for me to say, but I believe we have fulfilled the 40X4 slaps required by the bible and then some, as well as carrying the load for these countries for the extra mile. Jesus turned the money-lenders from out of the temple, it is time for use to turn out the oil sellers. It is high time to use the economic might that is the USA for it’s citizens benefit.
It would be an interesting study to look at the average cost of a barrel of oil and tie it to the average cost at the pump. Maybe we can look closer to home for some of the problems as well. Make the cost of a gallon of gas be a ratio to the cost of a barrel of oil.
Let’s do that with all medical supplies as well. It is pretty bad when many times folks in countries hostile to us can get medicine cheaper than we can…from a US company!
Last time I checked most food can be converted to alcohol, sure some is more efficient (corn) but just about anything we can digest and has sugar in it can be digested by yeast to produce alcohol, cars will run on that, as the oil companies have been saying ad-nauseam. As far as I know, it is rather more difficult to convert oil to food. Seems we have a bigger stick, not much grows in the desert, especially when there is no food to feed the workers.
Of course, we would have to harden ourselves to the site of hungry and starving children, that will be the first weapon they would use, pictures of their children. We would have to stifle the bleeding hearts out there. Perhaps if we stopped feeding the world for a loss they would start taking better care of their people. Most countries are only three-square meals away from revolution.
Tie it to the cost of electronics and other high tech items as well. Put a large tariff on technical talent, most of the oil wells out there wouldn’t be running without American know-how.
It is time for America to get tough. Time for us to harden our hearts a bit. As a Christian this hurts for me to say, but I believe we have fulfilled the 40X4 slaps required by the bible and then some, as well as carrying the load for these countries for the extra mile. Jesus turned the money-lenders from out of the temple, it is time for use to turn out the oil sellers. It is high time to use the economic might that is the USA for it’s citizens benefit.
Tuesday, April 18, 2006
A Pet Peeve
When will disk manufacturers join the rest of the industry? When you look at their specification sheets they do things like “320 Gigabyte Capacity (unformatted)” then you read further and in the footnotes it says “gigabyte is defined as 1000000000 bytes” so what does this really mean?
If you do the math, for the rest of the computer industry, a gigabyte is 1024 bytes cubed or 1073741824 bytes. This means the unformatted capacity of the drive is about 298 gigabytes or less. Assuming you only lose about 10% for formatting, this leaves you with 268 gigabytes, doesn’t sound near as impressive as 320 does it?
And how about stated transfer rates? On one manufacturers site they state that their disk can transfer data at 200 Mbytes per second on a fibre channel loop and about 320 Mbytes per second on a SCSI connection. Of course these numbers are really the transfer rates of the interface itself. When you look at the manuals it gives the true details, the maximum sustained transfer rate of the drive is actually 76 Mbyte/sec (with M being 1000000) so to the rest of the industry this is actually 72.5 Mbyte/sec. So to actually achieve the 200 Mbytes/sec (of course this is real Mbytes) you would need 3 of the drives. Since most systems will read a megabyte at a time, this 72.5 Mbyte/sec is roughly 73 IO/second.
Is it any wonder I go to site after site with IO issues? No wonder folks are confused. When you figure disk capacity in the last 20 years has gone from 30 megabytes on a hard drive to 300-500 gigabytes (a factor of 17067 increase) while disk transfer rates have only gone up by a factor of 20 or so it isn’t hard to see why people have difficulty specifying their disk systems in a meaningful way.
For example, I ran a report at a client that shows the Oracle system was performing an average of 480 IO/sec (taking the IO statistics from the v$filestat and v$tempstat views and the elapsed seconds since startup) realizing this is an average, I double this value to get a peak load (I know, that is probably too low) of 960 IO/sec. From our previous calculations if we use the 320 gig (right) disk, we will need 960/73 or 14 disks to support this systems peak IO load. Currently they use 4 drives and as load increases IO read times go from 2-3 milliseconds to over 20 milliseconds. The amount of data the system has is just less than a terabyte so in order to sustain the needed peak IO rate they need to buy 3.752 terabytes of disk, not even allowing for RAID10, or RAID5.
Kind of like having a huge dump truck with a Volkswagen beetle engine isn’t it? Unfortunately the disk manufacturers are coming up against the laws of physics, someone needs to tell them bigger is not better. We end up buying much more capacity than is needed just to get the IO rates we require.
Yes, I know there is caching both at the disk level and usually the array level, but many times this is only a few gigabytes. Shoot, anymore the reference tables in a large database will fill up the cache area and then you are back to disk speeds for access times.
With 500 (419 usable) gigabyte drives many of my client systems would fit on one drive if all we had to consider was volume, however you and I both know there are two sides to the capacity issue. You need to look at both disk volume and disk IO capacity. Another wrench in the works is the needed number of disks to support concurrent access. Believe me, while you can put a terabyte database on 3 of these huge drives you won’t support more than a couple of concurrent users before performance suffers.
So when you do your next disk purchase consider true formatted size and actual IO speed and compare that to your real IO requirements. Generally if you meet your needed IO and concurrent access requirements, you will more than meet the needed disk volume needs for your application.
If you do the math, for the rest of the computer industry, a gigabyte is 1024 bytes cubed or 1073741824 bytes. This means the unformatted capacity of the drive is about 298 gigabytes or less. Assuming you only lose about 10% for formatting, this leaves you with 268 gigabytes, doesn’t sound near as impressive as 320 does it?
And how about stated transfer rates? On one manufacturers site they state that their disk can transfer data at 200 Mbytes per second on a fibre channel loop and about 320 Mbytes per second on a SCSI connection. Of course these numbers are really the transfer rates of the interface itself. When you look at the manuals it gives the true details, the maximum sustained transfer rate of the drive is actually 76 Mbyte/sec (with M being 1000000) so to the rest of the industry this is actually 72.5 Mbyte/sec. So to actually achieve the 200 Mbytes/sec (of course this is real Mbytes) you would need 3 of the drives. Since most systems will read a megabyte at a time, this 72.5 Mbyte/sec is roughly 73 IO/second.
Is it any wonder I go to site after site with IO issues? No wonder folks are confused. When you figure disk capacity in the last 20 years has gone from 30 megabytes on a hard drive to 300-500 gigabytes (a factor of 17067 increase) while disk transfer rates have only gone up by a factor of 20 or so it isn’t hard to see why people have difficulty specifying their disk systems in a meaningful way.
For example, I ran a report at a client that shows the Oracle system was performing an average of 480 IO/sec (taking the IO statistics from the v$filestat and v$tempstat views and the elapsed seconds since startup) realizing this is an average, I double this value to get a peak load (I know, that is probably too low) of 960 IO/sec. From our previous calculations if we use the 320 gig (right) disk, we will need 960/73 or 14 disks to support this systems peak IO load. Currently they use 4 drives and as load increases IO read times go from 2-3 milliseconds to over 20 milliseconds. The amount of data the system has is just less than a terabyte so in order to sustain the needed peak IO rate they need to buy 3.752 terabytes of disk, not even allowing for RAID10, or RAID5.
Kind of like having a huge dump truck with a Volkswagen beetle engine isn’t it? Unfortunately the disk manufacturers are coming up against the laws of physics, someone needs to tell them bigger is not better. We end up buying much more capacity than is needed just to get the IO rates we require.
Yes, I know there is caching both at the disk level and usually the array level, but many times this is only a few gigabytes. Shoot, anymore the reference tables in a large database will fill up the cache area and then you are back to disk speeds for access times.
With 500 (419 usable) gigabyte drives many of my client systems would fit on one drive if all we had to consider was volume, however you and I both know there are two sides to the capacity issue. You need to look at both disk volume and disk IO capacity. Another wrench in the works is the needed number of disks to support concurrent access. Believe me, while you can put a terabyte database on 3 of these huge drives you won’t support more than a couple of concurrent users before performance suffers.
So when you do your next disk purchase consider true formatted size and actual IO speed and compare that to your real IO requirements. Generally if you meet your needed IO and concurrent access requirements, you will more than meet the needed disk volume needs for your application.
Monday, March 27, 2006
Further 1=2 Work
Added 4/4/2006 - Did a bit more probing via the 10gR2 explain plan tool. What Oracle actually does with the 1=2 is replace it with the predicate NULL IS NOT NULL. Simply use this instead of the 1=2 to eliminate some parsing and confusion in your code. This also seems to indicate you can replace the 1=1 with NULL IS NULL. Anyway, it's been some interesting research.
Finally having some spare time I decided to perform a few more tests on the 1=2 situation. In actuality it seems to be another case of Oracle explain plans not actually matching what is happening in the database.
Observe the following:
SQL> create table test as select * from dba_objects;
Table created.
SQL> select count(*) from test;
COUNT(*)
----------
50115
SQL> create index test_idx on test(object_id);
Index created.
SQL> analyze table test compute statistics;
Table analyzed.
SQL> set autotrace on
SQL> select count(object_id) from test where 1=2;
COUNT(OBJECT_ID)
----------------
0
Execution Plan
----------------------------------------------------------
0 SELECT STATEMENT Optimizer=ALL_ROWS (Cost=23 Card=1 Bytes=4)
1 0 SORT (AGGREGATE)
2 1 FILTER
3 2 INDEX (FAST FULL SCAN) OF 'TEST_IDX' (INDEX) (Cost=23
Card=50115 Bytes=200460)
Statistics
----------------------------------------------------------
1 recursive calls
0 db block gets
0 consistent gets
0 physical reads
0 redo size
310 bytes sent via SQL*Net to client
496 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1 rows processed
If we base our decision on cost, we see a cost of 23, but the true cost is in the statistics where it required only one recursive call, no db gets, consistent gets or physical reads. Now, if we flush the cache and shared pool we see the following:
SQL> alter system flush buffer_cache;
System altered.
SQL> alter system flush shared_pool;
System altered.
SQL> select count(object_id) from test where 1=2;
COUNT(OBJECT_ID)
----------------
0
Execution Plan
----------------------------------------------------------
0 SELECT STATEMENT Optimizer=ALL_ROWS (Cost=23 Card=1 Bytes=4)
1 0 SORT (AGGREGATE)
2 1 FILTER
3 2 INDEX (FAST FULL SCAN) OF 'TEST_IDX' (INDEX) (Cost=23
Card=50115 Bytes=200460)
Statistics
----------------------------------------------------------
297 recursive calls
0 db block gets
43 consistent gets
7 physical reads
0 redo size
310 bytes sent via SQL*Net to client
496 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
4 sorts (memory)
0 sorts (disk)
1 rows processed
So in adding parsing to the cost, we see that the recursive calls, consistent gets and physical reads do play a part, but only for the first execution. Now, dropping the index we see:
SQL> drop index test_idx;
Index dropped.
SQL> select count(object_id) from test where 1=2;
COUNT(OBJECT_ID)
----------------
0
Execution Plan
----------------------------------------------------------
0 SELECT STATEMENT Optimizer=ALL_ROWS (Cost=138 Card=1 Bytes=4
)
1 0 SORT (AGGREGATE)
2 1 FILTER
3 2 TABLE ACCESS (FULL) OF 'TEST' (TABLE) (Cost=138 Card=5
0115 Bytes=200460)
Statistics
----------------------------------------------------------
169 recursive calls
0 db block gets
18 consistent gets
0 physical reads
0 redo size
310 bytes sent via SQL*Net to client
496 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
3 sorts (memory)
0 sorts (disk)
1 rows processed
And now with cache and pool populated:
SQL> select count(object_id) from test where 1=2;
COUNT(OBJECT_ID)
----------------
0
Execution Plan
----------------------------------------------------------
0 SELECT STATEMENT Optimizer=ALL_ROWS (Cost=138 Card=1 Bytes=4
)
1 0 SORT (AGGREGATE)
2 1 FILTER
3 2 TABLE ACCESS (FULL) OF 'TEST' (TABLE) (Cost=138 Card=5
0115 Bytes=200460)
Statistics
----------------------------------------------------------
1 recursive calls
0 db block gets
0 consistent gets
0 physical reads
0 redo size
310 bytes sent via SQL*Net to client
496 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1 rows processed
Again we see that while the cost figure is several times higher than with the index, the true cost in recursive calls, db block gets and physical reads is the same as with the index.
Now what about with a comparison to an impossible column value? Let’s see:
SQL> create index test_idx on test(object_id);
Index created.
SQL> analyze table test compute statistics;
Table analyzed.
SQL> alter system flush shared_pool;
System altered.
SQL> alter system flush buffer_cache;
System altered.
SQL> select count(object_id) from test where object_id=0;
COUNT(OBJECT_ID)
----------------
0
Execution Plan
----------------------------------------------------------
0 SELECT STATEMENT Optimizer=ALL_ROWS (Cost=1 Card=1 Bytes=4)
1 0 SORT (AGGREGATE)
2 1 INDEX (RANGE SCAN) OF 'TEST_IDX' (INDEX) (Cost=1 Card=1
Bytes=4)
Statistics
----------------------------------------------------------
294 recursive calls
0 db block gets
44 consistent gets
18 physical reads
0 redo size
310 bytes sent via SQL*Net to client
496 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
4 sorts (memory)
0 sorts (disk)
1 rows processed
With parsing we see the cost in recursive calls, db block gets and physical reads is very similar to the costs using 1=2, but how about once the statement is loaded and the buffer cache filled? Let’s look:
SQL> /
COUNT(OBJECT_ID)
----------------
0
Execution Plan
----------------------------------------------------------
0 SELECT STATEMENT Optimizer=ALL_ROWS (Cost=1 Card=1 Bytes=4)
1 0 SORT (AGGREGATE)
2 1 INDEX (RANGE SCAN) OF 'TEST_IDX' (INDEX) (Cost=1 Card=1
Bytes=4)
Statistics
----------------------------------------------------------
0 recursive calls
0 db block gets
2 consistent gets
0 physical reads
0 redo size
310 bytes sent via SQL*Net to client
496 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1 rows processed
As you can see, the stated cost is much less, but the cost in consistent gets is 2. In timing, both statements showed a response time average of 0.05 seconds.
Conclusions
Oracle explain plans don’t always match what the database is doing, and costs can be next to useless in many situations always look at the underlying statistics to see what is happening. Always test in your own environment to ensure stated Oracle behavior from one OS to another remains constant.
As far as whether using 1=2 or using a comparison to an index column with a value that can’t exist is more efficient, using 1=2 is marginally better with 0 consistent gets verses 2 consistent gets however in performance tests the two statements performances where virtually indistinguishable.
Finally having some spare time I decided to perform a few more tests on the 1=2 situation. In actuality it seems to be another case of Oracle explain plans not actually matching what is happening in the database.
Observe the following:
SQL> create table test as select * from dba_objects;
Table created.
SQL> select count(*) from test;
COUNT(*)
----------
50115
SQL> create index test_idx on test(object_id);
Index created.
SQL> analyze table test compute statistics;
Table analyzed.
SQL> set autotrace on
SQL> select count(object_id) from test where 1=2;
COUNT(OBJECT_ID)
----------------
0
Execution Plan
----------------------------------------------------------
0 SELECT STATEMENT Optimizer=ALL_ROWS (Cost=23 Card=1 Bytes=4)
1 0 SORT (AGGREGATE)
2 1 FILTER
3 2 INDEX (FAST FULL SCAN) OF 'TEST_IDX' (INDEX) (Cost=23
Card=50115 Bytes=200460)
Statistics
----------------------------------------------------------
1 recursive calls
0 db block gets
0 consistent gets
0 physical reads
0 redo size
310 bytes sent via SQL*Net to client
496 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1 rows processed
If we base our decision on cost, we see a cost of 23, but the true cost is in the statistics where it required only one recursive call, no db gets, consistent gets or physical reads. Now, if we flush the cache and shared pool we see the following:
SQL> alter system flush buffer_cache;
System altered.
SQL> alter system flush shared_pool;
System altered.
SQL> select count(object_id) from test where 1=2;
COUNT(OBJECT_ID)
----------------
0
Execution Plan
----------------------------------------------------------
0 SELECT STATEMENT Optimizer=ALL_ROWS (Cost=23 Card=1 Bytes=4)
1 0 SORT (AGGREGATE)
2 1 FILTER
3 2 INDEX (FAST FULL SCAN) OF 'TEST_IDX' (INDEX) (Cost=23
Card=50115 Bytes=200460)
Statistics
----------------------------------------------------------
297 recursive calls
0 db block gets
43 consistent gets
7 physical reads
0 redo size
310 bytes sent via SQL*Net to client
496 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
4 sorts (memory)
0 sorts (disk)
1 rows processed
So in adding parsing to the cost, we see that the recursive calls, consistent gets and physical reads do play a part, but only for the first execution. Now, dropping the index we see:
SQL> drop index test_idx;
Index dropped.
SQL> select count(object_id) from test where 1=2;
COUNT(OBJECT_ID)
----------------
0
Execution Plan
----------------------------------------------------------
0 SELECT STATEMENT Optimizer=ALL_ROWS (Cost=138 Card=1 Bytes=4
)
1 0 SORT (AGGREGATE)
2 1 FILTER
3 2 TABLE ACCESS (FULL) OF 'TEST' (TABLE) (Cost=138 Card=5
0115 Bytes=200460)
Statistics
----------------------------------------------------------
169 recursive calls
0 db block gets
18 consistent gets
0 physical reads
0 redo size
310 bytes sent via SQL*Net to client
496 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
3 sorts (memory)
0 sorts (disk)
1 rows processed
And now with cache and pool populated:
SQL> select count(object_id) from test where 1=2;
COUNT(OBJECT_ID)
----------------
0
Execution Plan
----------------------------------------------------------
0 SELECT STATEMENT Optimizer=ALL_ROWS (Cost=138 Card=1 Bytes=4
)
1 0 SORT (AGGREGATE)
2 1 FILTER
3 2 TABLE ACCESS (FULL) OF 'TEST' (TABLE) (Cost=138 Card=5
0115 Bytes=200460)
Statistics
----------------------------------------------------------
1 recursive calls
0 db block gets
0 consistent gets
0 physical reads
0 redo size
310 bytes sent via SQL*Net to client
496 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1 rows processed
Again we see that while the cost figure is several times higher than with the index, the true cost in recursive calls, db block gets and physical reads is the same as with the index.
Now what about with a comparison to an impossible column value? Let’s see:
SQL> create index test_idx on test(object_id);
Index created.
SQL> analyze table test compute statistics;
Table analyzed.
SQL> alter system flush shared_pool;
System altered.
SQL> alter system flush buffer_cache;
System altered.
SQL> select count(object_id) from test where object_id=0;
COUNT(OBJECT_ID)
----------------
0
Execution Plan
----------------------------------------------------------
0 SELECT STATEMENT Optimizer=ALL_ROWS (Cost=1 Card=1 Bytes=4)
1 0 SORT (AGGREGATE)
2 1 INDEX (RANGE SCAN) OF 'TEST_IDX' (INDEX) (Cost=1 Card=1
Bytes=4)
Statistics
----------------------------------------------------------
294 recursive calls
0 db block gets
44 consistent gets
18 physical reads
0 redo size
310 bytes sent via SQL*Net to client
496 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
4 sorts (memory)
0 sorts (disk)
1 rows processed
With parsing we see the cost in recursive calls, db block gets and physical reads is very similar to the costs using 1=2, but how about once the statement is loaded and the buffer cache filled? Let’s look:
SQL> /
COUNT(OBJECT_ID)
----------------
0
Execution Plan
----------------------------------------------------------
0 SELECT STATEMENT Optimizer=ALL_ROWS (Cost=1 Card=1 Bytes=4)
1 0 SORT (AGGREGATE)
2 1 INDEX (RANGE SCAN) OF 'TEST_IDX' (INDEX) (Cost=1 Card=1
Bytes=4)
Statistics
----------------------------------------------------------
0 recursive calls
0 db block gets
2 consistent gets
0 physical reads
0 redo size
310 bytes sent via SQL*Net to client
496 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1 rows processed
As you can see, the stated cost is much less, but the cost in consistent gets is 2. In timing, both statements showed a response time average of 0.05 seconds.
Conclusions
Oracle explain plans don’t always match what the database is doing, and costs can be next to useless in many situations always look at the underlying statistics to see what is happening. Always test in your own environment to ensure stated Oracle behavior from one OS to another remains constant.
As far as whether using 1=2 or using a comparison to an index column with a value that can’t exist is more efficient, using 1=2 is marginally better with 0 consistent gets verses 2 consistent gets however in performance tests the two statements performances where virtually indistinguishable.
Thursday, March 23, 2006
WHERE 1=2 and Parallel Isn't
In another blog out there in blogspace a fellow expert has called me on this tip. I can only report what we saw during our testing. First we saw a reduction in full table scans as indicated in the V$SQL_PLAN with a reduction in the indicated bytes processed. Allowing that this may be just an artifact of Oracle reporting it would use a FTS if it actually tried to resolve the query but really used predicate elimination to realize there was nothing to do, how does one expalin away the drastic reduction in physical IO and logical IO we noticed in enterprise manager screens after the changes? Anyway, don't take my word for it, no one has the absolute last word on anything Oracle in less they are peering at the souce code for your release on your OS while making their pronouncements. Test the results on your machine and for your version and go with what works in your environment. It's just that simple.
Found out some interesting things yesterday. First, while reviewing a clients Oracle application which had been ported from SQL Server, I noticed they were using the constructs “WHERE 1=1” and “WHERE 1=2” in order to build dynamic SQL for dynamic queries. In the first case of “WHERE 1=1” it was always followed by a group of one or more “AND” clauses so the optimizer would of course practice predicate elimination and remove it. However in the second case, “WHERE 1=2” it was being used to merely return the column headers to avoid error handling.
It is this second case, “WHERE 1=2” I want to talk about. Of course since 1 never equals 2 you never get a result back, however it forces a full table scan! In testing with 10gR1 version 10.1.0.4 and on 9iR2, 9.2.0.4 if there was no bitmap index on the table using the “WHERE 1=2” construct resulted in a full table scan. I tried using a unique and a non-unique B-Tree and they were ignored, seems only a bitmap index would allow the optimizer to determine that 1 would never equal 2, why this is so is a mystery since obviously the bitmap had nothing to do with whether 1=1 or 1=2.
In SQL Server, the optimizer is smart enough to realize 1 will never equal 2 and there, it simply returns the column list without any other action. Oracle, you paying attention? Make a note!
What we ended up doing in this clients case was to replace the “WHERE 1=2” with a clause that equated the primary key of the table with an impossible value for that key, in this case the ID was being passed in as a GUID (a hexadecimal value) so we use a “WHERE KEY=HEX(00)” and got a low cost unique index lookup instead of a costly full table scan.
A second item of note, one of the tables in a SQL involved in a match against values passed into a global table temporary table had a PARALLEL setting of 4, but the instance had a parallel min servers setting of 0 so there was no way that a parallel scan could be performed. However, the fun part in this situation comes up when you get an explain plan. Using the command line explain plan you get a perfectly reasonable plan using an index scan on the permanent table and a full scan on the global temp. However, when you check on this SQL in the V$SQL_PLAN table it is attempted a parallel query with a single query slave doing a full table scan on both the permanent and temporary table!
The proper plan for this non-parallel query being forced into a non-optimal parallel plan was also shown in the EM database control session SQL screen (since it is probably pulled from the DBA_HIST_SQL_PLAN which is a child of the V$SQL_PLAN table, this makes sense.) However, the developer, using the PL/SQL Developer tool, was getting the bad explain plan and couldn’t see the problem. We changed the PARALLEL to 1 on the table and the plans then matched between the online explain plan and the V$SQL_PLAN explain plan.
A second note for Oracle: If the PARALLEL is set on a table and the MIN_PARALLEL_SERVERS is set to 0, completely disregard the PARALLEL setting. In testing a setting of 0 resulted in no P000 processes starting so even with the resulting parallel plan the query was serialized.
And a final note: The plan generated by the EXPLAIN PLAN and AUTOTRACE commands should match the one generated into the V$SQL_PLAN table.
Mike
Found out some interesting things yesterday. First, while reviewing a clients Oracle application which had been ported from SQL Server, I noticed they were using the constructs “WHERE 1=1” and “WHERE 1=2” in order to build dynamic SQL for dynamic queries. In the first case of “WHERE 1=1” it was always followed by a group of one or more “AND” clauses so the optimizer would of course practice predicate elimination and remove it. However in the second case, “WHERE 1=2” it was being used to merely return the column headers to avoid error handling.
It is this second case, “WHERE 1=2” I want to talk about. Of course since 1 never equals 2 you never get a result back, however it forces a full table scan! In testing with 10gR1 version 10.1.0.4 and on 9iR2, 9.2.0.4 if there was no bitmap index on the table using the “WHERE 1=2” construct resulted in a full table scan. I tried using a unique and a non-unique B-Tree and they were ignored, seems only a bitmap index would allow the optimizer to determine that 1 would never equal 2, why this is so is a mystery since obviously the bitmap had nothing to do with whether 1=1 or 1=2.
In SQL Server, the optimizer is smart enough to realize 1 will never equal 2 and there, it simply returns the column list without any other action. Oracle, you paying attention? Make a note!
What we ended up doing in this clients case was to replace the “WHERE 1=2” with a clause that equated the primary key of the table with an impossible value for that key, in this case the ID was being passed in as a GUID (a hexadecimal value) so we use a “WHERE KEY=HEX(00)” and got a low cost unique index lookup instead of a costly full table scan.
A second item of note, one of the tables in a SQL involved in a match against values passed into a global table temporary table had a PARALLEL setting of 4, but the instance had a parallel min servers setting of 0 so there was no way that a parallel scan could be performed. However, the fun part in this situation comes up when you get an explain plan. Using the command line explain plan you get a perfectly reasonable plan using an index scan on the permanent table and a full scan on the global temp. However, when you check on this SQL in the V$SQL_PLAN table it is attempted a parallel query with a single query slave doing a full table scan on both the permanent and temporary table!
The proper plan for this non-parallel query being forced into a non-optimal parallel plan was also shown in the EM database control session SQL screen (since it is probably pulled from the DBA_HIST_SQL_PLAN which is a child of the V$SQL_PLAN table, this makes sense.) However, the developer, using the PL/SQL Developer tool, was getting the bad explain plan and couldn’t see the problem. We changed the PARALLEL to 1 on the table and the plans then matched between the online explain plan and the V$SQL_PLAN explain plan.
A second note for Oracle: If the PARALLEL is set on a table and the MIN_PARALLEL_SERVERS is set to 0, completely disregard the PARALLEL setting. In testing a setting of 0 resulted in no P000 processes starting so even with the resulting parallel plan the query was serialized.
And a final note: The plan generated by the EXPLAIN PLAN and AUTOTRACE commands should match the one generated into the V$SQL_PLAN table.
Mike
Friday, March 03, 2006
They AMM to Please...Sometimes
Just an insteresting addition to this (3/16/2006) was at another client site where we saw this behavior on a 10gR2 Enterprise release of RAC as well. - Mike
Ran into another undocumented feature in 10gR2 Standard edition using RAC today. On a RedHat 4.0 4-CPU Opteron (2-Chip, 4-core) using 6 gigabytes of memory in a 2-node RAC, the client kept getting ORA-07445’s when their user load exceeded 60 users per node. At 100 users per node they were getting these errors, a coredump for each and a trace file on each server, for each node, about twice per minute. There didn’t seem to be any operational errors associated with it, but it seriously affected IO rates to the SAN and filled up the UDUMP and BDUMP areas quickly. Of course when the BDUMP area filled up the database tends to choke.
The client is using AMM with SGA_TARGET and SGA_MAX_SIZE set and no hard settings for the cache or shared pool sizes. Initially we filed an ITar or SR or whatever they are calling them these days but didn’t get much response on it. So the client suffered until I could get on site and do some looking.
I looked at memory foot print, CPU foot print and user logins and compared them to the incident levels of the ORA-07445. There was a clear correlation to the number of users and memory usage. Remembering that the resize operations are recorded I then looked in the GV$SGA_RESIZE_OPS DPV and then correlated the various memory operations to the incidences of the ORA-07445, the errors only seemed to occur when a shrink occurred in the shared pool as we saw the error on node 1 where a shrink occurred and none on node 2 where no shrink had happened yet.
Sure enough, hard setting the SHARED_POOL_SIZE to a minimum value delayed the error so that it didn’t start occurring until the pool extended above the minimum then shrank back to it, however, not every time. We were able to boost the number of users to 80 before the error started occurring by hard setting the shared pool to 250 megabytes. A further boost to the shared pool size to 300 megabytes seems to have corrected the issue so far but we will have to monitor this as the number of user processes increases. Note that you need to look at the GV$SGA_RESIZE_OPS DPV to see what resize operations are occurring and the peak size reached to find the correct setting on your system.
It appears that there must some internal list of HASH values that is not being cleaned up when the shared pool is shrunk. This results in the kernel expecting to find a piece of code at a particular address, looking for it and not finding it, this generates the ORA-07445. Of course this is just speculation on my part.
So for you folks using 10gR2 Standard edition with RAC (not sure if it happens with Non-RAC, non-Standard) look at either not using AMM, or be sure to hard set the SHARED_POOL_SIZE to a value that can service your number of expected users and their code and dictionary needs.
Ran into another undocumented feature in 10gR2 Standard edition using RAC today. On a RedHat 4.0 4-CPU Opteron (2-Chip, 4-core) using 6 gigabytes of memory in a 2-node RAC, the client kept getting ORA-07445’s when their user load exceeded 60 users per node. At 100 users per node they were getting these errors, a coredump for each and a trace file on each server, for each node, about twice per minute. There didn’t seem to be any operational errors associated with it, but it seriously affected IO rates to the SAN and filled up the UDUMP and BDUMP areas quickly. Of course when the BDUMP area filled up the database tends to choke.
The client is using AMM with SGA_TARGET and SGA_MAX_SIZE set and no hard settings for the cache or shared pool sizes. Initially we filed an ITar or SR or whatever they are calling them these days but didn’t get much response on it. So the client suffered until I could get on site and do some looking.
I looked at memory foot print, CPU foot print and user logins and compared them to the incident levels of the ORA-07445. There was a clear correlation to the number of users and memory usage. Remembering that the resize operations are recorded I then looked in the GV$SGA_RESIZE_OPS DPV and then correlated the various memory operations to the incidences of the ORA-07445, the errors only seemed to occur when a shrink occurred in the shared pool as we saw the error on node 1 where a shrink occurred and none on node 2 where no shrink had happened yet.
Sure enough, hard setting the SHARED_POOL_SIZE to a minimum value delayed the error so that it didn’t start occurring until the pool extended above the minimum then shrank back to it, however, not every time. We were able to boost the number of users to 80 before the error started occurring by hard setting the shared pool to 250 megabytes. A further boost to the shared pool size to 300 megabytes seems to have corrected the issue so far but we will have to monitor this as the number of user processes increases. Note that you need to look at the GV$SGA_RESIZE_OPS DPV to see what resize operations are occurring and the peak size reached to find the correct setting on your system.
It appears that there must some internal list of HASH values that is not being cleaned up when the shared pool is shrunk. This results in the kernel expecting to find a piece of code at a particular address, looking for it and not finding it, this generates the ORA-07445. Of course this is just speculation on my part.
So for you folks using 10gR2 Standard edition with RAC (not sure if it happens with Non-RAC, non-Standard) look at either not using AMM, or be sure to hard set the SHARED_POOL_SIZE to a value that can service your number of expected users and their code and dictionary needs.
Monday, January 23, 2006
Adjusting Array Size in Oracle SQL*Plus
The default ARRAYSIZE in SQL*PLus is 15. This will show up during the analysis of the trace files by dividing the number of rows returned by the number of SQLNet roundtrips as the default size being using in the application. The ARRAYSIZE specifies the number of rows to return when returning a set of values to the application. Since this specifies the array size to return, it directly impacts the number of round trips required to satisfy a request for data.
I ran a series of select statements using the SQL*Plus interface to a development environment and varied the ARRAYSIZE starting at 5 and working up to 200 in increments of five. The following chart shows the results for the example select statement:
SELECT * FROM dba_objects;
I utilized the SET AUTOTRACE ON STATISTICS and SET TIMING ON commands to gather statistics on net round trips and time required to satisfy the select statement.
Where this can be of real benefit is in a Java situation. To set the array size, use the setDefaultRowPrefetch method of the OracleConnection class. However, the size should be determined empirically by setting the size and running test runs because this is a case of diminishing returns as the array size gets larger. Also, the size of network buffers and packets need to be factored in when sizing the buffers in SQL.
I ran a series of select statements using the SQL*Plus interface to a development environment and varied the ARRAYSIZE starting at 5 and working up to 200 in increments of five. The following chart shows the results for the example select statement:
SELECT * FROM dba_objects;
I utilized the SET AUTOTRACE ON STATISTICS and SET TIMING ON commands to gather statistics on net round trips and time required to satisfy the select statement.
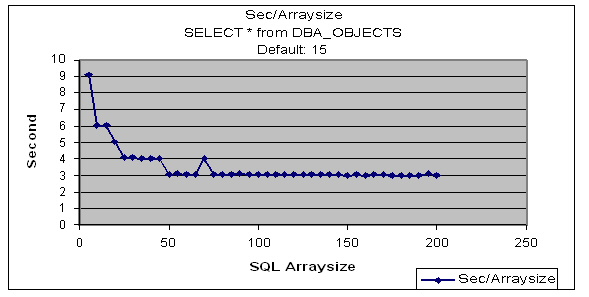
As you can see the benefits for this select statement fall off after an ARRAYSIZE of 50 is reached. A plot of the roundtrips verses ARRAYSIZE tells why. In the following chart of roundtrips verses ARRAYSIZE setting you see that at 50 the value for roundtrips is 147 having reduced from the high of 1606 by 90%, from array sizes 50 to 200 it only decreases to 42 a change of only 10% (based on the original 1606) fewer roundtrips.

Where this can be of real benefit is in a Java situation. To set the array size, use the setDefaultRowPrefetch method of the OracleConnection class. However, the size should be determined empirically by setting the size and running test runs because this is a case of diminishing returns as the array size gets larger. Also, the size of network buffers and packets need to be factored in when sizing the buffers in SQL.
Friday, January 20, 2006
Much Ado About Nothing
Well actually, a NULL is UNKOWN not the absence of a value. But how would “Much Ado About Unknown” sound as a title?
I had to explain to a fellow DBA the impact of null on processing where the columns that where null were also used in joining of tables. It took a while, but finally he caught on. It made me wonder how many folks are confused by this. The major issue is that nulls are not tracked in normal indexes. It is true that while bitmap indexes may be used to track null values, they have their own issues for OLTP environments and usually have very restricted use in OLTP environments.
I decided to develop a little test case just to show what is going on with NULLs. Let’s take a look at this test case:
SQL> create table test as select * from dba_objects;
Table created.
SQL> desc test
Name Null? Type
----------------------------------------- -------- ----------------------------
OWNER VARCHAR2(30)
OBJECT_NAME VARCHAR2(128)
SUBOBJECT_NAME VARCHAR2(30)
OBJECT_ID NUMBER
DATA_OBJECT_ID NUMBER
OBJECT_TYPE VARCHAR2(18)
CREATED DATE
LAST_DDL_TIME DATE
TIMESTAMP VARCHAR2(19)
STATUS VARCHAR2(7)
TEMPORARY VARCHAR2(1)
GENERATED VARCHAR2(1)
SECONDARY VARCHAR2(1)
SQL> create index test_ind on test(object_id);
Index created.
SQL> analyze table test compute statistics;
Table analyzed.
SQL> set autotrace on
SQL> select count(*) from test where object_id is not null;
COUNT(*)
----------
33732
Execution Plan
----------------------------------------------------------
0 SELECT STATEMENT Optimizer=CHOOSE (Cost=19 Card=1 Bytes=4)
1 0 SORT (AGGREGATE)
2 1 INDEX (FAST FULL SCAN) OF 'TEST_IND' (NON-UNIQUE) (Cost=
19 Card=33732 Bytes=134928)
Statistics
----------------------------------------------------------
0 recursive calls
0 db block gets
79 consistent gets
0 physical reads
0 redo size
381 bytes sent via SQL*Net to client
499 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1 rows processed
SQL> select count(*) from test where object_id is null;
COUNT(*)
----------
11
Execution Plan
----------------------------------------------------------
0 SELECT STATEMENT Optimizer=CHOOSE (Cost=104 Card=1 Bytes=4)
1 0 SORT (AGGREGATE)
2 1 TABLE ACCESS (FULL) OF 'TEST' (Cost=104 Card=11 Bytes=44
)
Statistics
----------------------------------------------------------
0 recursive calls
0 db block gets
464 consistent gets
0 physical reads
0 redo size
379 bytes sent via SQL*Net to client
499 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1 rows processed
SQL>
SQL> create index fbi_test on test(nvl(object_id,-1));
Index created.
SQL> analyze table test compute statistics;
Table analyzed.
SQL> select count(*) from test where nvl(object_id,-1)=-1;
COUNT(*)
----------
11
Execution Plan
----------------------------------------------------------
0 SELECT STATEMENT Optimizer=CHOOSE (Cost=2 Card=1 Bytes=4)
1 0 SORT (AGGREGATE)
2 1 INDEX (RANGE SCAN) OF 'FBI_TEST' (NON-UNIQUE) (Cost=2 Ca
rd=12 Bytes=48)
Statistics
----------------------------------------------------------
0 recursive calls
0 db block gets
2 consistent gets
0 physical reads
0 redo size
379 bytes sent via SQL*Net to client
499 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1 rows processed
SQL> update test set object_id=-1 where object_id is null;
11 rows updated.
Execution Plan
----------------------------------------------------------
0 UPDATE STATEMENT Optimizer=CHOOSE (Cost=104 Card=11 Bytes=44
)
1 0 UPDATE OF 'TEST'
2 1 TABLE ACCESS (FULL) OF 'TEST' (Cost=104 Card=11 Bytes=44
)
Statistics
----------------------------------------------------------
2 recursive calls
78 db block gets
465 consistent gets
0 physical reads
9208 redo size
625 bytes sent via SQL*Net to client
548 bytes received via SQL*Net from client
3 SQL*Net roundtrips to/from client
2 sorts (memory)
0 sorts (disk)
11 rows processed
SQL> commit;
Commit complete.
SQL> select count(*) from test where object_id=-1;
COUNT(*)
----------
11
Execution Plan
----------------------------------------------------------
0 SELECT STATEMENT Optimizer=CHOOSE (Cost=2 Card=1 Bytes=4)
1 0 SORT (AGGREGATE)
2 1 INDEX (RANGE SCAN) OF 'TEST_IND' (NON-UNIQUE) (Cost=2 Ca
rd=1 Bytes=4)
Statistics
----------------------------------------------------------
0 recursive calls
0 db block gets
2 consistent gets
0 physical reads
0 redo size
379 bytes sent via SQL*Net to client
499 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1 rows processed
1. We create a test table with nulls in the column OBJECT_ID
2. We then created a normal index on the OBJECT_ID column
3. Using IS NULL and IS NOT NULL based WHERE clauses we determined:
I had to explain to a fellow DBA the impact of null on processing where the columns that where null were also used in joining of tables. It took a while, but finally he caught on. It made me wonder how many folks are confused by this. The major issue is that nulls are not tracked in normal indexes. It is true that while bitmap indexes may be used to track null values, they have their own issues for OLTP environments and usually have very restricted use in OLTP environments.
I decided to develop a little test case just to show what is going on with NULLs. Let’s take a look at this test case:
SQL> create table test as select * from dba_objects;
Table created.
SQL> desc test
Name Null? Type
----------------------------------------- -------- ----------------------------
OWNER VARCHAR2(30)
OBJECT_NAME VARCHAR2(128)
SUBOBJECT_NAME VARCHAR2(30)
OBJECT_ID NUMBER
DATA_OBJECT_ID NUMBER
OBJECT_TYPE VARCHAR2(18)
CREATED DATE
LAST_DDL_TIME DATE
TIMESTAMP VARCHAR2(19)
STATUS VARCHAR2(7)
TEMPORARY VARCHAR2(1)
GENERATED VARCHAR2(1)
SECONDARY VARCHAR2(1)
SQL> create index test_ind on test(object_id);
Index created.
SQL> analyze table test compute statistics;
Table analyzed.
SQL> set autotrace on
SQL> select count(*) from test where object_id is not null;
COUNT(*)
----------
33732
Execution Plan
----------------------------------------------------------
0 SELECT STATEMENT Optimizer=CHOOSE (Cost=19 Card=1 Bytes=4)
1 0 SORT (AGGREGATE)
2 1 INDEX (FAST FULL SCAN) OF 'TEST_IND' (NON-UNIQUE) (Cost=
19 Card=33732 Bytes=134928)
Statistics
----------------------------------------------------------
0 recursive calls
0 db block gets
79 consistent gets
0 physical reads
0 redo size
381 bytes sent via SQL*Net to client
499 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1 rows processed
SQL> select count(*) from test where object_id is null;
COUNT(*)
----------
11
Execution Plan
----------------------------------------------------------
0 SELECT STATEMENT Optimizer=CHOOSE (Cost=104 Card=1 Bytes=4)
1 0 SORT (AGGREGATE)
2 1 TABLE ACCESS (FULL) OF 'TEST' (Cost=104 Card=11 Bytes=44
)
Statistics
----------------------------------------------------------
0 recursive calls
0 db block gets
464 consistent gets
0 physical reads
0 redo size
379 bytes sent via SQL*Net to client
499 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1 rows processed
SQL>
SQL> create index fbi_test on test(nvl(object_id,-1));
Index created.
SQL> analyze table test compute statistics;
Table analyzed.
SQL> select count(*) from test where nvl(object_id,-1)=-1;
COUNT(*)
----------
11
Execution Plan
----------------------------------------------------------
0 SELECT STATEMENT Optimizer=CHOOSE (Cost=2 Card=1 Bytes=4)
1 0 SORT (AGGREGATE)
2 1 INDEX (RANGE SCAN) OF 'FBI_TEST' (NON-UNIQUE) (Cost=2 Ca
rd=12 Bytes=48)
Statistics
----------------------------------------------------------
0 recursive calls
0 db block gets
2 consistent gets
0 physical reads
0 redo size
379 bytes sent via SQL*Net to client
499 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1 rows processed
SQL> update test set object_id=-1 where object_id is null;
11 rows updated.
Execution Plan
----------------------------------------------------------
0 UPDATE STATEMENT Optimizer=CHOOSE (Cost=104 Card=11 Bytes=44
)
1 0 UPDATE OF 'TEST'
2 1 TABLE ACCESS (FULL) OF 'TEST' (Cost=104 Card=11 Bytes=44
)
Statistics
----------------------------------------------------------
2 recursive calls
78 db block gets
465 consistent gets
0 physical reads
9208 redo size
625 bytes sent via SQL*Net to client
548 bytes received via SQL*Net from client
3 SQL*Net roundtrips to/from client
2 sorts (memory)
0 sorts (disk)
11 rows processed
SQL> commit;
Commit complete.
SQL> select count(*) from test where object_id=-1;
COUNT(*)
----------
11
Execution Plan
----------------------------------------------------------
0 SELECT STATEMENT Optimizer=CHOOSE (Cost=2 Card=1 Bytes=4)
1 0 SORT (AGGREGATE)
2 1 INDEX (RANGE SCAN) OF 'TEST_IND' (NON-UNIQUE) (Cost=2 Ca
rd=1 Bytes=4)
Statistics
----------------------------------------------------------
0 recursive calls
0 db block gets
2 consistent gets
0 physical reads
0 redo size
379 bytes sent via SQL*Net to client
499 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1 rows processed
1. We create a test table with nulls in the column OBJECT_ID
2. We then created a normal index on the OBJECT_ID column
3. Using IS NULL and IS NOT NULL based WHERE clauses we determined:
a. The IS NOT NULL type WHERE clause will use an index
b. The IS NULL type WHERE doesn’t use an index
4. Next we create a function base index using the NVL function to convert the NULL values into a default value.
When we use the NVL function in our SELECT in place of the IS NULL we get index usage and much better performance, however, this may lead to improper relationships between tables.
5. As a final step, we replace the NULL values in TEST with a default value of -1, now using that in our select instead of IS NULL we get response virtually identical with the use of NVL function based index.
Of course the issues we are trying to prevent with all this is processing of IS NULL type queries forcing such items as full table scans and causing developers to have to use OUTER JOIN type syntax to resolve NULL conditions between tables. By eliminating these OUTER JOIN and IS NULL processing steps which result in large HASH and full table scans in many cases, we can dramatically reduce the execution times of queries. Notice in the example how we reduced cost figures from 104 for a full table scan to 2 for an index (either our normal or the function based index) scan.
So, what should we take from this? Several conclusions can be reached:
- Whenever possible avoid the use of NULLable columns for columns that will be joined.
- Use default values in place of NULL, note that to avoid outer joins, both parent and child tables must have a value, for example if we had a parent table the related to the OBJECT_ID in our example, we would have an entry of (-1, ‘NO ID’) in that parent to resolve the -1 entries in the child.
- If IS NULL is required, consider replacing it with a NVL call and a function based index, while this may not help with outer joins, it will help with IS NULL type selects.
Have fun!
Mike
Tuesday, January 03, 2006
New Years Day Dive
I got up this morning and built a tank rack. A tank rack holds scuba tanks so they don’t do major damage to you, your vehicle or themselves rolling wily-nily about the back of your vehicle. I did this feat of carpentry legerdemain because I was going to meet up the infamous Lake Lanier Loonies for their annual New Years Day dive and picnic.
So what you are probably saying. Well, even though we are in the “south” part of the states (Georgia) our nightly temperatures hover around freezing this time of year and even today it only reached a balmy 57 degrees Fahrenheit. The lake is undergoing turnover, which means there is no warm layer, it was a uniform 47 degrees from the top down to the depths we planned on diving. Now you can see where the Loony part of the name comes from.
Even when it is at its peak summer temperatures Lake Lanier rarely gets above 60 degrees below its thermocline. On a good day you use a 3mm wetsuit. For 47 degrees you use 5-7mm full wetsuits with hood and gloves, 5-7 mm shorties with hood, boots and gloves or a drysuit. I thought I had it covered with a 5mm drysuit I had been assured was a large and would fit me after I described myself (accurately) to the seller.
The night before I had decided, since this would be the first dive of the drysuit, that I had better learn how to put the thing on without making a big fool of myself. I put on my swimsuit and a lycra dive skin (a dive skin is a lightweight suit, think of a whole-body leotard). The next step involved unzipping the drysuit, the zipper goes from the middle back all the way around between the legs to the upper chest. You begin donning the drysuit by inserting your legs into the legs of the suit, think of 5 mm (one half inch) thick panty hose with a sealing ring at the ankle and you will get the idea. The next step is to simply (right) stick your arms into the arms (again, think of 5mm panty hose for your arms with seal rings at the wrists) and at the same time thrust your head up through the neck seal into the tight hood. The neck seal is like the tightest turtleneck sweater you can imagine.
Anyway, I got the arms in, got the head started and then realized I had run out of standup room in the suit. As I stood there hunched over with the neck seal tight around my forehead I glanced on one of the inside panels where I hadn’t had a chance to look before. I suddenly realized why I had run out of room and if I had succeeded in thrusting my head through the seal I would have instantly regretted it. All it took was one small word, “Medium” scrawled in permanent marker.
Since by design I am a extra-large type of guy, had I succeeded in thrusting my size 16 and half neck into the medium size neck seal I probably would have choked to death before a I could have got the thing off. Needless to say I was a bit upset. I had expected to get two 3mm wetsuits the previous week, one for my wife and one for me, which I could have used as a 6mm combo in a pinch, but alas, they fell prey to the holiday mails so here I was, the day before the dive, a holiday, no dry or wet suit capable of making the dive. I posted to the Scubaboard website my predicament. A fellow Looney came to my rescue, seems he had a 5mm “shorty”, a suit with no boots or hood, that he could let me use and was, as I, an XL kind of guy. So, here we are back at were I began the story.
After I built the tank rack I placed into it both my personal and a rental tank, both loaded to 3000 PSI of air, and strapped it down to the bed of my Montero. We then loaded up the other dive gear, some broiled chicken and warm drinks and drove the 20 some miles to the West Bank Park at Lake Lanier where we met, for the first time, with the other Loonies.
The Loonies are a diverse lot, from instructors and dive masters to the barely qualified, nine intrepid divers ready to face the challenges of Lake Lanier, some driving for over an hour and a half for the privilege. While on shore waited our wives, bravely smiling and laughing as we struggled into our dive gear, hiding their fears, at least I hope they were just hiding their fears, I noticed none of them were diving…
We finished donning our dive gear and marched proudly, well, as proudly as you can walking backward since you are wearing fins, into the water. The suit I was borrowing was a 5 mm wetsuit, as its name implies, it is designed to allow a small bit of water in next to your skin, your body heat warms it and it acts as an insulation layer, as long as there isn’t too much water flow. Needless to say, the first five-to-ten minutes of any dive in cold water with a wetsuit are always interesting as you warm the cold (in this case 47 degree) water up to body temperature. After the first ten minutes I was actually pretty comfortable except for my hands. Afraid I only had on what are known as “reef” gloves, they are used to protect your hands from rough reef surfaces, not to keep them warm.
We finally were able to turn around once we got to mid-chest level and could start to swim out to deeper water. I had on strap-on fins since I was wearing dive boots. Usually I use a pair of full-foot fins (Velocity model) that have a bit of flex to them. The strap-on ones find felt like a couple of boards since they were much stiffer than what I was used to. So what should have been a fairly easy swim was a bit more difficult, but manageable.
Finally we got out to about 15 feet of water. I pulled my mask up over my face (only rookies keep it up on the forehead, which is actually a distress signal) and just then a wave filled my mouth with wonderful Lake Lanier Water. After coughing and hacking and scaring my dive buddies, I finally got my breath back and placed my regulator into my mouth. After a look around and a synchronization of watches we held our BCD inflator hoses over our head and releasing the air that was holding us on the surface slid like German U-boats (well, more like distressed seals) beneath the cold water’s surface.
I would like to report that we had excellent visibility and it was grand, however, I don’t like to lie. Visibility was about 6-8 feet, this is not so good, even for Lake Lanier. Lake Lanier can have visibility of 10-15 feet above the thermocline and even more below the thermocline, however, when the lake is turning over, visibility gets pretty bad. After sinking though 8 feet of moss-green water we had to switch on our dive lights. I was using one of my Christmas presents, a small UK40 light that attaches to your mask strap for hands free operation. Unfortunately when you look at other divers straight on, you end up blinding them, something my dive buddy pointed out to me after the dive by telling me if I ever used that light with it hooked to my mask strap again he would mount somewhere the light don’t shine…wonder what he meant?
Anyway, our assignment was to proceed to a structure known as “the lumber yard” which was a pile of submerged timber at a heading of 45 degrees east of the main swim marker buoys and place a dive buoy over it so one of the other divers could do a laser sighting and range calculation for a diver’s map of the features. We proceeded down the underwater incline, 20 feet, 30 feet, 50 feet when suddenly I saw the dive leader stop and start messing with his dive computer. He signaled me to come over and show him mine, which I did. It seems his had stopped displaying. We found out later his battery was at the near-end-of-life level and would work fine topside, as soon as it cooled down the voltage would drop and the computer would switch off its display.
The lumber yard was supposedly at 75 feet. After messing around along the bottom for a while we came upon some large logs, not a bunch, but a few, we assumed this was the lumber yard so we placed the buoy and swam back on our reciprocal heading. Only once did the silt we kicked up from the bottom cause me to get disoriented and temporarily lose site of my dive partners, but I rose enough to get out of the brown-silt filled bottom water and up into the murky-green water and soon spotted their dive lights and with a prayer of thanks rejoined them. It would have been the height of embarrassment to be the new-kid and get lost from my dive buddies.
Since the dive leader’s computer was malfunctioning and we were all nearing less than 1000 PSI on our tanks he decided to halt the dive and return to shore. Giving the thumbs up signal which means “let’s surface” we all three went vertical, held our inflators over our heads and vented our BCDs, kicking for the surface. If you don’t vent the BCD's they can rapidly expand as you decrease depth and rocket you to the surface, if you return to the surface too fast you risk decompression sickness, commonly called the bends. Besides, your dive computer will yell at you with rather loud beeps if you ascend too quickly and let everyone know you are being bad.
We reached the surface safely after having reached a maximum depth of 67 feet and spending 26 minutes in the cold murky water and back pedaled to shallow water, where we once again walked backward out to the shore. Walking backward like that felt like we were in a movie someone had placed in reverse. I really prefer boat dives, it is just more dramatic to do a back roll from the gunwale or a giant stride from a dive platform into the water and forcefully pulling your way up a dive ladder than this trudging backward stuff.
Now came the real hard part, taking off the wet gear. As the dive suit is exposed to air the evaporative cooling from the air can chill you quickly. Again we had the snickers and smiles from the women folk to contend with as we struggled with our gear. Of course my Susan came over and helped me, sometimes it is rather tough to get the shoulders off in a front zip suit.
After everyone else returned from the dive we went up the hill to the barbecue grill and had a wonderful picnic. All in all it was a great day. Even though the dive was cold, dark, murky and we saw nothing but some old logs, suspended algae and silt and a lot of bottom mud, it still beat a day at the office. I’ll be back next year!
New Years Dive Profile
So what you are probably saying. Well, even though we are in the “south” part of the states (Georgia) our nightly temperatures hover around freezing this time of year and even today it only reached a balmy 57 degrees Fahrenheit. The lake is undergoing turnover, which means there is no warm layer, it was a uniform 47 degrees from the top down to the depths we planned on diving. Now you can see where the Loony part of the name comes from.
Even when it is at its peak summer temperatures Lake Lanier rarely gets above 60 degrees below its thermocline. On a good day you use a 3mm wetsuit. For 47 degrees you use 5-7mm full wetsuits with hood and gloves, 5-7 mm shorties with hood, boots and gloves or a drysuit. I thought I had it covered with a 5mm drysuit I had been assured was a large and would fit me after I described myself (accurately) to the seller.
The night before I had decided, since this would be the first dive of the drysuit, that I had better learn how to put the thing on without making a big fool of myself. I put on my swimsuit and a lycra dive skin (a dive skin is a lightweight suit, think of a whole-body leotard). The next step involved unzipping the drysuit, the zipper goes from the middle back all the way around between the legs to the upper chest. You begin donning the drysuit by inserting your legs into the legs of the suit, think of 5 mm (one half inch) thick panty hose with a sealing ring at the ankle and you will get the idea. The next step is to simply (right) stick your arms into the arms (again, think of 5mm panty hose for your arms with seal rings at the wrists) and at the same time thrust your head up through the neck seal into the tight hood. The neck seal is like the tightest turtleneck sweater you can imagine.
Anyway, I got the arms in, got the head started and then realized I had run out of standup room in the suit. As I stood there hunched over with the neck seal tight around my forehead I glanced on one of the inside panels where I hadn’t had a chance to look before. I suddenly realized why I had run out of room and if I had succeeded in thrusting my head through the seal I would have instantly regretted it. All it took was one small word, “Medium” scrawled in permanent marker.
Since by design I am a extra-large type of guy, had I succeeded in thrusting my size 16 and half neck into the medium size neck seal I probably would have choked to death before a I could have got the thing off. Needless to say I was a bit upset. I had expected to get two 3mm wetsuits the previous week, one for my wife and one for me, which I could have used as a 6mm combo in a pinch, but alas, they fell prey to the holiday mails so here I was, the day before the dive, a holiday, no dry or wet suit capable of making the dive. I posted to the Scubaboard website my predicament. A fellow Looney came to my rescue, seems he had a 5mm “shorty”, a suit with no boots or hood, that he could let me use and was, as I, an XL kind of guy. So, here we are back at were I began the story.
After I built the tank rack I placed into it both my personal and a rental tank, both loaded to 3000 PSI of air, and strapped it down to the bed of my Montero. We then loaded up the other dive gear, some broiled chicken and warm drinks and drove the 20 some miles to the West Bank Park at Lake Lanier where we met, for the first time, with the other Loonies.
The Loonies are a diverse lot, from instructors and dive masters to the barely qualified, nine intrepid divers ready to face the challenges of Lake Lanier, some driving for over an hour and a half for the privilege. While on shore waited our wives, bravely smiling and laughing as we struggled into our dive gear, hiding their fears, at least I hope they were just hiding their fears, I noticed none of them were diving…
We finished donning our dive gear and marched proudly, well, as proudly as you can walking backward since you are wearing fins, into the water. The suit I was borrowing was a 5 mm wetsuit, as its name implies, it is designed to allow a small bit of water in next to your skin, your body heat warms it and it acts as an insulation layer, as long as there isn’t too much water flow. Needless to say, the first five-to-ten minutes of any dive in cold water with a wetsuit are always interesting as you warm the cold (in this case 47 degree) water up to body temperature. After the first ten minutes I was actually pretty comfortable except for my hands. Afraid I only had on what are known as “reef” gloves, they are used to protect your hands from rough reef surfaces, not to keep them warm.
We finally were able to turn around once we got to mid-chest level and could start to swim out to deeper water. I had on strap-on fins since I was wearing dive boots. Usually I use a pair of full-foot fins (Velocity model) that have a bit of flex to them. The strap-on ones find felt like a couple of boards since they were much stiffer than what I was used to. So what should have been a fairly easy swim was a bit more difficult, but manageable.
Finally we got out to about 15 feet of water. I pulled my mask up over my face (only rookies keep it up on the forehead, which is actually a distress signal) and just then a wave filled my mouth with wonderful Lake Lanier Water. After coughing and hacking and scaring my dive buddies, I finally got my breath back and placed my regulator into my mouth. After a look around and a synchronization of watches we held our BCD inflator hoses over our head and releasing the air that was holding us on the surface slid like German U-boats (well, more like distressed seals) beneath the cold water’s surface.
I would like to report that we had excellent visibility and it was grand, however, I don’t like to lie. Visibility was about 6-8 feet, this is not so good, even for Lake Lanier. Lake Lanier can have visibility of 10-15 feet above the thermocline and even more below the thermocline, however, when the lake is turning over, visibility gets pretty bad. After sinking though 8 feet of moss-green water we had to switch on our dive lights. I was using one of my Christmas presents, a small UK40 light that attaches to your mask strap for hands free operation. Unfortunately when you look at other divers straight on, you end up blinding them, something my dive buddy pointed out to me after the dive by telling me if I ever used that light with it hooked to my mask strap again he would mount somewhere the light don’t shine…wonder what he meant?
Anyway, our assignment was to proceed to a structure known as “the lumber yard” which was a pile of submerged timber at a heading of 45 degrees east of the main swim marker buoys and place a dive buoy over it so one of the other divers could do a laser sighting and range calculation for a diver’s map of the features. We proceeded down the underwater incline, 20 feet, 30 feet, 50 feet when suddenly I saw the dive leader stop and start messing with his dive computer. He signaled me to come over and show him mine, which I did. It seems his had stopped displaying. We found out later his battery was at the near-end-of-life level and would work fine topside, as soon as it cooled down the voltage would drop and the computer would switch off its display.
The lumber yard was supposedly at 75 feet. After messing around along the bottom for a while we came upon some large logs, not a bunch, but a few, we assumed this was the lumber yard so we placed the buoy and swam back on our reciprocal heading. Only once did the silt we kicked up from the bottom cause me to get disoriented and temporarily lose site of my dive partners, but I rose enough to get out of the brown-silt filled bottom water and up into the murky-green water and soon spotted their dive lights and with a prayer of thanks rejoined them. It would have been the height of embarrassment to be the new-kid and get lost from my dive buddies.
Since the dive leader’s computer was malfunctioning and we were all nearing less than 1000 PSI on our tanks he decided to halt the dive and return to shore. Giving the thumbs up signal which means “let’s surface” we all three went vertical, held our inflators over our heads and vented our BCDs, kicking for the surface. If you don’t vent the BCD's they can rapidly expand as you decrease depth and rocket you to the surface, if you return to the surface too fast you risk decompression sickness, commonly called the bends. Besides, your dive computer will yell at you with rather loud beeps if you ascend too quickly and let everyone know you are being bad.
We reached the surface safely after having reached a maximum depth of 67 feet and spending 26 minutes in the cold murky water and back pedaled to shallow water, where we once again walked backward out to the shore. Walking backward like that felt like we were in a movie someone had placed in reverse. I really prefer boat dives, it is just more dramatic to do a back roll from the gunwale or a giant stride from a dive platform into the water and forcefully pulling your way up a dive ladder than this trudging backward stuff.
Now came the real hard part, taking off the wet gear. As the dive suit is exposed to air the evaporative cooling from the air can chill you quickly. Again we had the snickers and smiles from the women folk to contend with as we struggled with our gear. Of course my Susan came over and helped me, sometimes it is rather tough to get the shoulders off in a front zip suit.
After everyone else returned from the dive we went up the hill to the barbecue grill and had a wonderful picnic. All in all it was a great day. Even though the dive was cold, dark, murky and we saw nothing but some old logs, suspended algae and silt and a lot of bottom mud, it still beat a day at the office. I’ll be back next year!
New Years Dive Profile
Thursday, December 22, 2005
On Vacation...
Well, I'm on holiday vacation down in Florida. The wife and I got to do something we wanted to do for a long time, we snorkeled with the Manatees in Crystal River. These gentle sea mammals known as sea cows are on the endangered species list with less than 2500 of them still around.
In the Crystal River area 1500 or so of these spend the winter in the warm springs (72 degrees year round) that abound in this area of Florida. Anyway, we saw about a half dozen and most came over to us and wanted to be scratched and petted just like big dogs. We had one that was smaller than a person, but most where anywhere from 10-15 feet long and weighed up to 1200 or more pounds.
The biggest hazard to these gentle herbivores is man. Between speed boats, fishing boats and other forms of propeller driven transport we kill many of these gentle giants each year. What aren't killed directly from collision may die from infection from the serious wounds. One we petted showed a series of parallel scars form being struck by a boat sometime in the past. What Manatees aren't killed by boats are affected by the red-tides caused by warmer water, pollution and algae-blooms some scientists say are being made more deadly because of global warming.
Anyway, we thoroughly enjoyed the snorkeling and the gentle Manatees. Afterward I got to do a cavern dive into the spring cavern near the Manatee reserve. The cavern water was clear and warmer than the outside water. Inside were many interesting items such as fossils and of course, the spring itself. Well, back to vacation!

Susan Petting Manatee
In the Crystal River area 1500 or so of these spend the winter in the warm springs (72 degrees year round) that abound in this area of Florida. Anyway, we saw about a half dozen and most came over to us and wanted to be scratched and petted just like big dogs. We had one that was smaller than a person, but most where anywhere from 10-15 feet long and weighed up to 1200 or more pounds.
The biggest hazard to these gentle herbivores is man. Between speed boats, fishing boats and other forms of propeller driven transport we kill many of these gentle giants each year. What aren't killed directly from collision may die from infection from the serious wounds. One we petted showed a series of parallel scars form being struck by a boat sometime in the past. What Manatees aren't killed by boats are affected by the red-tides caused by warmer water, pollution and algae-blooms some scientists say are being made more deadly because of global warming.
Anyway, we thoroughly enjoyed the snorkeling and the gentle Manatees. Afterward I got to do a cavern dive into the spring cavern near the Manatee reserve. The cavern water was clear and warmer than the outside water. Inside were many interesting items such as fossils and of course, the spring itself. Well, back to vacation!

Susan Petting Manatee
Wednesday, November 30, 2005
Becoming Non-Dimensional
No, I am not talking about switching into some star-trek universe, however, this may help deliver warp-speed performance!
Dimensionless Star Schema (Bitmap Star)
Introduction
In standard data warehousing we are taught to utilize a central fact table surrounded by multiple dimension tables. The dimension tables contain, for lack of a better description, report headers and maybe a description, usually they are very lean tables. In Oracle9i and later these dimensions are then related to the fact table by means of bitmap indexes on the foreign key columns in the fact table.
Examination of a Star Schema
So in closer examination we have three major components in a star:
- Central Fact table
- Dimension tables
- Bitmap indexes on foreign keys
Note that in Oracle9i and later the actual foreign keys do not have to be declared, but the bitmap indexes must be present.
So when a star is searched the outer dimension tables are first scanned then the bitmaps are merged based on the results from the scan of the dimension tables and the fact table is then sliced and diced based on the bitmap merges. Generally the dimension tables have little more than the lookup value, maybe a description, maybe a count or sum. In most cases the measures stored in the dimension tables can be easily derived, especially for counts and sums.
This all points to an interesting thought, in the case where the dimension table actually adds nothing to the data available, but merely serves as a scan table for values stored in the database, why not eliminate it all together and simply create the bitmap index on the fact table as if it did exist? Many dimension tables can be eliminated in this fashion.
A New Star is Born
Eliminating most, if not all of a fact tables dimension tables but leaving the bitmap indexes in place on what were the foreign keys leaves us with what I call a bitmap star. By eliminating the fact tables we reduce our maintenance and storage requirements and may actually improve the performance of our queries that now simply do a bitmap merge operation to resolve the query, eliminating many un-needed table and index operations from the now defunct dimensions.
Essentially you are flattening the structure into a potentially sparse fact table that is heavily bitmap indexed. The bitmap indexes become the “dimensions” in this new structure.
Caveat Emptor!
However, this structure is not suitable for all star schemas but can be applied in a limited fashion to many where the duplicitous storage of values in both the fact and dimension tables occurs. The applicability of this structure has to be determined on a case by case basis and is not a suggested one-size-fits-all solution for all data warehouses.
If I get some spare time I will create some test cases to try out this new structure in comparison to a traditional star schema. In tests of the bitmap star we achieved sub-second response time utilizing Oracle Discoverer against a 2.5 million row bitmap star table built on a 7-disk RAID5 array. The fact table had 6 bitmap indexes and one 5-column primary key index. Only a single “normal” dimension table was required due to a needed additional breakout of values on one of the columns in the fact table.
Wednesday, October 26, 2005
Through the Looking Glass: 10gR2 RAC Installation
On my most recent assignment I had the dubious pleasure of installing Oracle10g Release 2 for a RAC installation on an OCFS2 file system on RedHat 4.0 on a Xeon 64 bit system. Of course the first issue is, as of this writing the OCFS2 file system is not certified for use in RedHat4.o -64 bit with 10gR2 RAC. Just because 10gR2 is the latest RAC and OCFS2 is the latest cluster file system from Oracle don’t let that confuse you…far be it for me to state they should work together.
The client had the boxes up and running just as asked, of course we had to add a few packages, notably the config libraries that don’t get installed with the base “total” install of RedHat, the vim editor and a couple of other convenience packages. We also were using iscsi which had yet to be configured. However within a day we had the iscsi running over Gig Enet to a Left-Hand disk array and OCFS2 up and running.
Next of course you install Cluster Ready Services. The client had the latest install disks sent directly from Oracle. I loaded the DVD and commenced installation. Other than the new screens, such as multiple OCR configuration files (they now allow a mirror, bravo!) and multiple voting disk locations (up to three, another kudo) the screens are similar to the ones we know and love. However, once it got to the final screen where it does the actual install, link, configuration and setup is where the fun began.
On the link step the system complained:
### Error Messages: ###
INFO: Start output from spawned process:
INFO: ----------------------------------
INFO:
INFO: /var/oracle/product/10.2.0/crs/bin/genclntsh
INFO: /usr/bin/ld: skipping incompatible /var/oracle/product/10.2.0/crs/lib/libxml10.a when searching for -lxml10/usr/bin/ld: cannot find -lxml10
INFO: collect2: ld returned 1 exit status
INFO: genclntsh: Failed to link libclntsh.so.10.1
INFO: make: *** [client_sharedlib] Error 1
INFO: End output from spawned process.
INFO: ----------------------------------
The lxm10 module deals with XML parsing in the client stack, so naturally the first thing out of Oracle support was: OCFS2 is NOT yet certified to use with RHEL4.0 10g R2 in RAC env.
Workaround is to use:
a) raw device or ASM
b) RHEL3 with OCFS1
So, please go to a supported config and if the problem still persists, please update this TAR.
Huh? What the heck does OCSF2 have to do with the XML parsing library not being found? We were not using a shared ORACLE_HOME and were not using OCFS2 for anything yet (that doesn’t happen until root.sh is run on the last step).
After getting to a duty manager we were able to get a bit more help. Next, after uploading several sets of logs and traces that all said basically the same thing (lxml10 was missing) it was suggested that perhaps downloading the OTN version might help since it was newer.
This we did. It linked. Now I realize this is a radical suggestion, but shouldn’t Oracle QC have taken one of the production run DVDs and did a full test install on the target platform before making it available?
Call me crazy I guess…but it seems to me something this obvious would have been caught by a one-eyed QC inspector with one arm tied behind his back wearing an ipod blasting heavy metal into his ears while driving down the 101 freeway watching the install on his web enabled cell phone…
Now we got to root.sh execution, and of course it went without a hitch…not! Next we got:
/var/oracle/product/10.2.0/crs/bin/crsctl create scr oracle/var/oracle/product/10.2.0/crs/bin/crsctl.bin:
error while loading shared libraries:
libstdc++.so.5: cannot open shared object file:
No such file or directory
/bin/echo Failure initializing entries in /etc/oracle/scls_scr/rhora1.
Long sigh….the LD_LIBRARY_PATH shows the /usr/lib as being a part of it, and the libstdc++.so.5 soft link to libstdc++.so.5.0.7 library is there, as is the links target library. I even tried placing a softlink to the libstdc++.so.5.0.7 in /usr/lib in the $ORACLE_CRS/lib directory (calling it libstdc++.so.5 of course). Can’t wait to see the next response from support… Will keep you all posted!
Latest news: We found the DVD ordered/sent was the X86 not the X86_64 version, however, since the library in the first issue is from the DVD seems like it is still an issue. However, the downloaded version is definitely X86_64. Of course the latest twist is even though support asked us to download and see if it would install they now say since we loaded a downloaded version it is not supported until we get new CDs. You just can't win...however, the support analyst says he is still pursuing the issue internally and will keep the tar open. Someone is showing some sense!
While we were waiting I decided to check the reboot on both machines. During a reboot command the system issues a call to the halt command which stops all processes, this causes the system to spin on the ocfs2 o2hb_bio_end_io:222 Error: IO error -5 because the ocfs2 filesystems are not unmounted yet. We have attempted to place the umount commands into an init.d script and run it at priorities as high as 2 however, it seems the init scripts are run after the halt command so it does no good.
The question now becomes: How can we force the unmount of the OCFS2 filesystems before the halt call during a shutdown/reboot?
The latest response on our sev 2 TAR:
Thank you for the update. The owning support engineer, xxxx.AU, has gone off shift for the weekend in Australia and is not currently available; however, they will have the opportunity to review and progress the issue during their next scheduled shift. In the mean time, if you feel that this is a critical down production issue or an issue for which you require prompt assistance from an available support engineer, please advise us of this specifically by phoning your local support number (see http://www.oracle.com/support/contact.html for a listing) to advise call response of your need for attention; otherwise, no update is required on your part at this time and xxxx.AU will follow-up with you during their next scheduled shift.
Ok, we bought it that OCFS2 is not supported. We switched to RAWS and used them, got the same error on CRS install. Week after next if nothing new from Oracle we back track to 10gR1 and go with RAWs and ASM.
First lesson learned...Oracle demands the libstdc.so.5 library it will accept no substitutions! The only thing Oracle helped with so far...but we had to find the issue and the proper RPM to install.
Second lesson learned...do not use links with the raws needed for CRS (2 for the config disk and its mirror and 3, yes 3! for the voting disks) or the root.sh will fail. Once we went directly to the raw devices themselves CRS installed. Solved this ourselves.
Third lesson learned...Oracle expects routable IP addresses on the VIP if it doesn't get it them the cluster configuration verification step fails (ignore it if you use unroutable IPs) and the vipca silent install will fail at the end of the root.sh, just run it manually from the command line. We found this ourselves after first error.
Fourth Lesson Learned: Don't let the SA configure the entire system disk as one large partition, leave room to add swap if needed.
Fifth Lesson: If the ssh won't equivilize on the second (third, fourth..etc) node even though you've done everything right, on the offending node do this:
Login as oracle user:
$ cd $HOME
$ chmod 755 .
$ chmod 700 .ssh
$ cd $HOME/.ssh
$ chmod 600 authorized_keys
Also, to get rid of the annoying last login message, which will result in an error, add this to your sshd_config file on the RAC system nodes:
PrintMotd no
PrintLastLog no
Now on to the actual database and ASM install. I can't wait...
Well...ASM wouldn't link properly... so:
Article-ID: Note 339367.1
Title: Installing 10.2.0.1 Db On A Redhat Linux X86-64 Os Version 4.0, Errors
SOLUTION/ACTION PLAN
=====================
To implement the solution, please execute the following steps:
Download this file at http://oss.oracle.com/projects/compat-oracle/files/RedHat/Red Hat:
binutils-2.15.92.0.2-13.0.0.0.2.x86_64.rpm 2005.10.05
RHEL 4 Update 1 patched binutils necessary for 10gR2 install on x86_64
Then try the relink all again
Ok...now everything worked but lsnrctl threw segmentation faults, so...
Article-ID: Note 316746.1 (Which by the way, can't be found on metalink)
Title: Segmentation Fault When Execute Sqlplus, Oracle, Lsnrctl After New/Patchset Install
ACTION PLAN
============
Please do the following:
1. cd /usr/bin (as root)
2. mv gcc gcc.script
3. mv g++ g++.script
4. ln -s gcc32 gcc
5. ln -s g++32 g++
6. login as oracle software owner (make sure environment is correct)
7. cd $ORACLE_HOME/bin
8. $ script /tmp/env_relink.out
9. $ env 10. $ ls -l /usr/bin
11. $ relink all
12. $ exit
13. Send env_relink.out to Oracle support
Finally! A system with CRS running, OracleNet running and ASM running hopefully ready for the databases to be created...11/17/2005.
Isn't attention to prompt and courteous customer support a wonderful thing?
Mike
The client had the boxes up and running just as asked, of course we had to add a few packages, notably the config libraries that don’t get installed with the base “total” install of RedHat, the vim editor and a couple of other convenience packages. We also were using iscsi which had yet to be configured. However within a day we had the iscsi running over Gig Enet to a Left-Hand disk array and OCFS2 up and running.
Next of course you install Cluster Ready Services. The client had the latest install disks sent directly from Oracle. I loaded the DVD and commenced installation. Other than the new screens, such as multiple OCR configuration files (they now allow a mirror, bravo!) and multiple voting disk locations (up to three, another kudo) the screens are similar to the ones we know and love. However, once it got to the final screen where it does the actual install, link, configuration and setup is where the fun began.
On the link step the system complained:
### Error Messages: ###
INFO: Start output from spawned process:
INFO: ----------------------------------
INFO:
INFO: /var/oracle/product/10.2.0/crs/bin/genclntsh
INFO: /usr/bin/ld: skipping incompatible /var/oracle/product/10.2.0/crs/lib/libxml10.a when searching for -lxml10/usr/bin/ld: cannot find -lxml10
INFO: collect2: ld returned 1 exit status
INFO: genclntsh: Failed to link libclntsh.so.10.1
INFO: make: *** [client_sharedlib] Error 1
INFO: End output from spawned process.
INFO: ----------------------------------
The lxm10 module deals with XML parsing in the client stack, so naturally the first thing out of Oracle support was: OCFS2 is NOT yet certified to use with RHEL4.0 10g R2 in RAC env.
Workaround is to use:
a) raw device or ASM
b) RHEL3 with OCFS1
So, please go to a supported config and if the problem still persists, please update this TAR.
Huh? What the heck does OCSF2 have to do with the XML parsing library not being found? We were not using a shared ORACLE_HOME and were not using OCFS2 for anything yet (that doesn’t happen until root.sh is run on the last step).
After getting to a duty manager we were able to get a bit more help. Next, after uploading several sets of logs and traces that all said basically the same thing (lxml10 was missing) it was suggested that perhaps downloading the OTN version might help since it was newer.
This we did. It linked. Now I realize this is a radical suggestion, but shouldn’t Oracle QC have taken one of the production run DVDs and did a full test install on the target platform before making it available?
Call me crazy I guess…but it seems to me something this obvious would have been caught by a one-eyed QC inspector with one arm tied behind his back wearing an ipod blasting heavy metal into his ears while driving down the 101 freeway watching the install on his web enabled cell phone…
Now we got to root.sh execution, and of course it went without a hitch…not! Next we got:
/var/oracle/product/10.2.0/crs/bin/crsctl create scr oracle/var/oracle/product/10.2.0/crs/bin/crsctl.bin:
error while loading shared libraries:
libstdc++.so.5: cannot open shared object file:
No such file or directory
/bin/echo Failure initializing entries in /etc/oracle/scls_scr/rhora1.
Long sigh….the LD_LIBRARY_PATH shows the /usr/lib as being a part of it, and the libstdc++.so.5 soft link to libstdc++.so.5.0.7 library is there, as is the links target library. I even tried placing a softlink to the libstdc++.so.5.0.7 in /usr/lib in the $ORACLE_CRS/lib directory (calling it libstdc++.so.5 of course). Can’t wait to see the next response from support… Will keep you all posted!
Latest news: We found the DVD ordered/sent was the X86 not the X86_64 version, however, since the library in the first issue is from the DVD seems like it is still an issue. However, the downloaded version is definitely X86_64. Of course the latest twist is even though support asked us to download and see if it would install they now say since we loaded a downloaded version it is not supported until we get new CDs. You just can't win...however, the support analyst says he is still pursuing the issue internally and will keep the tar open. Someone is showing some sense!
While we were waiting I decided to check the reboot on both machines. During a reboot command the system issues a call to the halt command which stops all processes, this causes the system to spin on the ocfs2 o2hb_bio_end_io:222 Error: IO error -5 because the ocfs2 filesystems are not unmounted yet. We have attempted to place the umount commands into an init.d script and run it at priorities as high as 2 however, it seems the init scripts are run after the halt command so it does no good.
The question now becomes: How can we force the unmount of the OCFS2 filesystems before the halt call during a shutdown/reboot?
The latest response on our sev 2 TAR:
Thank you for the update. The owning support engineer, xxxx.AU, has gone off shift for the weekend in Australia and is not currently available; however, they will have the opportunity to review and progress the issue during their next scheduled shift. In the mean time, if you feel that this is a critical down production issue or an issue for which you require prompt assistance from an available support engineer, please advise us of this specifically by phoning your local support number (see http://www.oracle.com/support/contact.html for a listing) to advise call response of your need for attention; otherwise, no update is required on your part at this time and xxxx.AU will follow-up with you during their next scheduled shift.
Ok, we bought it that OCFS2 is not supported. We switched to RAWS and used them, got the same error on CRS install. Week after next if nothing new from Oracle we back track to 10gR1 and go with RAWs and ASM.
First lesson learned...Oracle demands the libstdc.so.5 library it will accept no substitutions! The only thing Oracle helped with so far...but we had to find the issue and the proper RPM to install.
Second lesson learned...do not use links with the raws needed for CRS (2 for the config disk and its mirror and 3, yes 3! for the voting disks) or the root.sh will fail. Once we went directly to the raw devices themselves CRS installed. Solved this ourselves.
Third lesson learned...Oracle expects routable IP addresses on the VIP if it doesn't get it them the cluster configuration verification step fails (ignore it if you use unroutable IPs) and the vipca silent install will fail at the end of the root.sh, just run it manually from the command line. We found this ourselves after first error.
Fourth Lesson Learned: Don't let the SA configure the entire system disk as one large partition, leave room to add swap if needed.
Fifth Lesson: If the ssh won't equivilize on the second (third, fourth..etc) node even though you've done everything right, on the offending node do this:
Login as oracle user:
$ cd $HOME
$ chmod 755 .
$ chmod 700 .ssh
$ cd $HOME/.ssh
$ chmod 600 authorized_keys
Also, to get rid of the annoying last login message, which will result in an error, add this to your sshd_config file on the RAC system nodes:
PrintMotd no
PrintLastLog no
Now on to the actual database and ASM install. I can't wait...
Well...ASM wouldn't link properly... so:
Article-ID: Note 339367.1
Title: Installing 10.2.0.1 Db On A Redhat Linux X86-64 Os Version 4.0, Errors
SOLUTION/ACTION PLAN
=====================
To implement the solution, please execute the following steps:
Download this file at http://oss.oracle.com/projects/compat-oracle/files/RedHat/Red Hat:
binutils-2.15.92.0.2-13.0.0.0.2.x86_64.rpm 2005.10.05
RHEL 4 Update 1 patched binutils necessary for 10gR2 install on x86_64
Then try the relink all again
Ok...now everything worked but lsnrctl threw segmentation faults, so...
Article-ID: Note 316746.1 (Which by the way, can't be found on metalink)
Title: Segmentation Fault When Execute Sqlplus, Oracle, Lsnrctl After New/Patchset Install
ACTION PLAN
============
Please do the following:
1. cd /usr/bin (as root)
2. mv gcc gcc.script
3. mv g++ g++.script
4. ln -s gcc32 gcc
5. ln -s g++32 g++
6. login as oracle software owner (make sure environment is correct)
7. cd $ORACLE_HOME/bin
8. $ script /tmp/env_relink.out
9. $ env 10. $ ls -l /usr/bin
11. $ relink all
12. $ exit
13. Send env_relink.out to Oracle support
Finally! A system with CRS running, OracleNet running and ASM running hopefully ready for the databases to be created...11/17/2005.
Isn't attention to prompt and courteous customer support a wonderful thing?
Mike
Sunday, October 16, 2005
Bureaucracy at its Finest
A young, recently married, couple I know did something few would have the courage or conviction to do. They gave up their jobs, sold or stored their possessions and joined the Peace Corps. I wish I could say that they finished their training, have been assigned to an interesting post and are enthusiastically pursuing their new endeavor together. Unfortunately that is not the case.
Upon arrival to their training assignment, as I understand it, they were informed that they have no place to stay. Then they were informed that it would be at least another three months before a training slot became available and then they probably couldn’t be trained, or assigned together. They were then sent back home. Needless to say, they are both very upset and have completely reversed their decision to join the Peace Corps. The Peace Corps is losing two fine candidates, and the young couple a great life enhancing opportunity, all through bureaucratic incompetence.
Luckily both of the couple are well qualified (one is a teacher, the other has a good degree) so finding new jobs or getting back the jobs they left should not be a problem. However, the shear order of magnitude of the bureaucratic incompetence shown in this episode is staggering. To send people thousands of miles away from home, spending thousands of tax dollars to do so, only to not have housing, not have the training available and finally to tell them that even if they tough it out they wouldn’t be assigned together just boggles the mind. Has to make you wonder how well they are tracking their personnel in the field and what level of support they are providing to them.
In this day of terrorist activity, kidnappings and hate of all things American that these young people would be willing to, at great personal risk, serve others is highly commendable. That they cannot fulfill this desire to be of service to others due to the stupidity and incompetence of others is deplorable.
Upon arrival to their training assignment, as I understand it, they were informed that they have no place to stay. Then they were informed that it would be at least another three months before a training slot became available and then they probably couldn’t be trained, or assigned together. They were then sent back home. Needless to say, they are both very upset and have completely reversed their decision to join the Peace Corps. The Peace Corps is losing two fine candidates, and the young couple a great life enhancing opportunity, all through bureaucratic incompetence.
Luckily both of the couple are well qualified (one is a teacher, the other has a good degree) so finding new jobs or getting back the jobs they left should not be a problem. However, the shear order of magnitude of the bureaucratic incompetence shown in this episode is staggering. To send people thousands of miles away from home, spending thousands of tax dollars to do so, only to not have housing, not have the training available and finally to tell them that even if they tough it out they wouldn’t be assigned together just boggles the mind. Has to make you wonder how well they are tracking their personnel in the field and what level of support they are providing to them.
In this day of terrorist activity, kidnappings and hate of all things American that these young people would be willing to, at great personal risk, serve others is highly commendable. That they cannot fulfill this desire to be of service to others due to the stupidity and incompetence of others is deplorable.
Subscribe to:
Posts (Atom)
